Altair physicsAI는 모든 CAE 유저들에게 향상된 geometric deep learning을 제공합니다. HyperWorks 2022.3 버전부터 CAE 데이터를 활용하여 physics prediction이 가능한 physicsAI가 포함되었고, 사용자 피드백을 듣고 개선하기 위해 노력을 기울였습니다. HyperWorks 2023 부터는 사용성 및 범용성을 늘리는데 중점을 뒀습니다.
그럼 지금부터 physicsAI에 관해 가장 많이 묻는 질문 13가지에 대한 답변을 데이터 및 형식, 컴퓨팅 및 리소스, 정확성 및 품질의 세 가지 범주로 분류하여 말씀드리겠습니다.
(1) 데이터 및 형식
Q. 학습 데이터에는 어떤 형식의 파일(format)이 지원되나요?
A. physicsAI의 파일 읽기 기술은 HyperView와 같은 HyperWorks 생태계를 통해 공통적으로 사용됩니다. (H3D파일 사용을 가장 선호합니다)
Q. transient 시뮬레이션이 지원됩니까?
A. 예, static 시뮬레이션과 transient 시뮬레이션이 모두 지원됩니다.
※ transient 시뮬레이션의 결과 time step이 같아야 합니다.
Q. 예측을 위한 학습모델에 얼마나 많은 데이터가 필요합니까?
A. 좋은 품질의 예측을 얻는 데 필요한 결과 파일의 수는 프로젝트마다 다릅니다.
형상, 결과, 해석의 복잡성과 데이터의 수에 따라 일부 프로젝트에서는 소수의 결과 파일만 필요할 수도 있고 다른 프로젝트에서는 수십 또는 수백 개의 결과 파일이 필요할 수도 있습니다.
또한 충분한 품질의 예측은 그 자체로 주관적인 평가입니다.
일반적인 가이드로, 최소 10개 이상의 결과로 학습하는 것이 좋습니다.
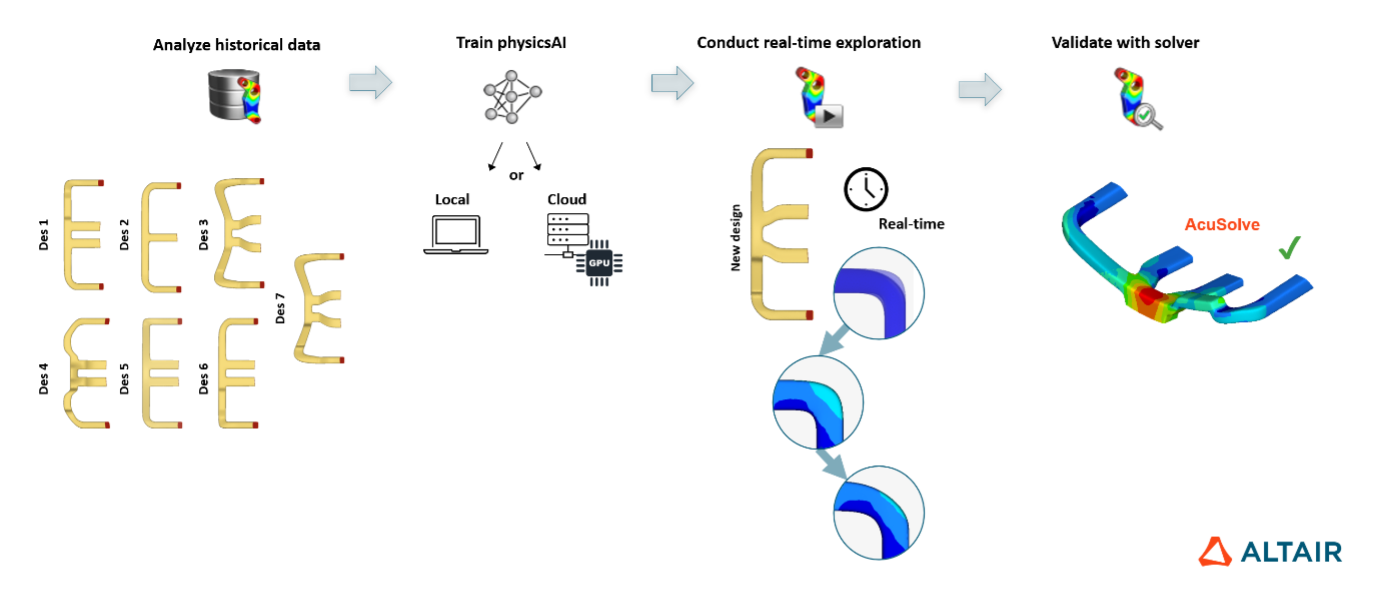
Q. 메쉬에는 동일한 수의 요소/노드가 있어야 합니까?
A. 아니요, 동등한 메쉬가 필요하지 않습니다. 아래 이미지에서 볼 수 있듯이 메시는 위상적으로 동일할 필요도 없습니다.
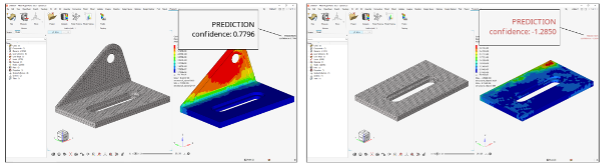
Q. Training에 사용되는 데이터의 형상이 얼마나 달라야 하나요?
A. Training 데이터에 허용되는 변형에는 특별한 제한이 없습니다.
그러나 2가지 사항을 고려해야 합니다.
첫째, Training데이터는 예측이 이루어질 새로운 설계(형상)를 대표, 포함해야 합니다.
둘째, 변동성이 높은 데이터 세트에는 품질을 유지하기 위해 그에 상응하는 더 많은 수의 Training데이터(결과 파일)가 필요합니다.
예측할 때 신뢰도(confidence) 점수를 사용하여 새 디자인이 훈련 데이터와 얼마나 유사한지 수치화할 수 있습니다.
(2) 컴퓨팅 및 리소스
Q. GPU가 필요합니까?
A. 아니요. CPU를 사용하여 모델을 training할 수 있지만 GPU보다 속도가 느립니다.
Q. 어떤 GPU가 지원되나요?
A. GPU를 사용하여 training하려면 CUDA 툴킷 11.8 및 cuDNN 8.7을 설치해야 합니다. 이를 위해서는 최소한 Pascal 마이크로아키텍처, 즉 compute capability > 6.0의 NVIDIA GPU가 필요합니다.
Q. GPU와 데이터세트 크기는 training 시간에 어떤 영향을 미치나요?
A. 더 좋은 CPU는 런타임을 줄일 수 있지만, CPU에서 GPU로의 개선은 훨씬 더 좋은 성능을 기대할 수 있습니다. 하드웨어에 관계없이 training 시간은 데이터세트 크기에 대략 선형적으로 비례합니다. 대표적인 예는 아래 차트를 참조하세요.
| 10 result files | 50 result files | 100 result files | |
| Laptop CPU | 44 m | 3 h 35 m | 7 h 54 m |
| HPC CPU | 34 m | 2 h 46 m | 5 h 10 m |
| GPU | 3 m | 16m | 33 m |
Q. HPC에서 training 할 수 있나요?
A. 예, 자세한 내용은 HELP Document에서 확인하세요.
(3) 정확성과 품질
Q. 정확성은 어떤가요?
A. 일반적으로 정확도는 데이터 양, 모델의 학습 파라미터(예: width, depth, epoch), 할당된 training 시간에 따라 향상될 수 있습니다.
그러나 실제적으로 이러한 설정들을 정의하는 것에는 제한이 있습니다. trained 모델의 품질 평가는 training 프로세스의 마지막 단계입니다.
이는 예를 들어 테스트 데이터 세트의 MAE와 같이 알려진 값을 이용하게 됩니다.
Q. 좋은 MAE란 무엇인가요?
A. MAE는 mean absolute error입니다. MAE는 예측(prediction)의 오류 값으로 이해할 수 있습니다. 예를 들어, MAE가 4mm인 변위를 예측하는 모델을 생각해 보면, 주어진 예측이 평균 4mm 정도 부정확할 수 있다고 해석할 수 있습니다. 엔지니어링 관심 대상으로 예상되는 변위가 5mm에 불과한 경우 이는 중요할 수 있지만 값이 500mm인 경우에는 덜 중요할 수 있습니다.
Q. 학습 파라미터를 어떻게 설정해야 합니까?
A. 프로젝트마다 다릅니다. 기본 설정으로 시작하는 것이 좋지만 가장 좋은 방법은 충분히 높은 품질의 모델을 얻을 수 있도록 설정을 조정하는 것입니다. 동일한 데이터세트에서 모델을 반복적으로 학습하여 다양한 설정에 걸쳐 결과를 비교할 수 있습니다. 이러한 실험은 유사한 프로젝트 진행 시 유사한 설정에서 최상의 결과를 얻을 수 있다는 실증적 증거를 제공할 수 있습니다.
Q. trained 모델이 솔버를 대체할 수 있나요?
A. 그럴 수도, 아닐 수도 있습니다. 모델은 솔버의 빠른 근사치로 작동하도록 설계되었으므로 일반적으로 솔버 수준의 정확도를 기대하지 않습니다. 일반적으로 솔버보다 1~3배 더 빠릅니다. 이는 솔버 수준의 정확도를 달성하지 못하더라도 유용할 수 있습니다. 이를 통해 새로운 디자인 컨셉을 빠르게 탐색할 수 있기 때문입니다. 최종 디자인은 솔버를 사용하여 검증해야 합니다. 즉, 적절한 training 데이터와 설정이 주어지면 모델을 비교적 정확하게 훈련할 수 있습니다.
글을 마치며…
physicalAI를 지원하는 기술은 계속해서 확장될 것입니다. 이것은 단지 먼 미래의 비전이 아닙니다. 툴은 이미 소프트웨어에 내장되어 있습니다. 몇 번 클릭으로 PhysicalAI를 사용할 수 있습니다! 아직 사용해 보지 않으셨다면, 최신 버전의 HyperWorks를 사용하여 누구나 AI 기반 디자인을 시작하는 것이 얼마나 쉬운지 확인하십시오.

![[무료 평가판] 데이터, 시뮬레이션, HPC 무료로 사용해보세요!](https://blog.altair.co.kr/wp-content/uploads/Altair-FreeTrial_AltairOne-500x383.jpg)