GPU의 작동 상태를 이해하고 작업 스케줄러의 결정에 GPU의 상태를 통합하는 것은 사용자에게 최적의 작업 배치를 보장하는 데 유용합니다. 또한 관리자가 리소스 할당을 계획하는 데 GPU 리소스의 사용을 이해하는 데 도움이 됩니다.
일본에서 가장 오래된 학술 슈퍼컴퓨팅 센터인 도쿄대학교는 HPC와 심층 학습 응용 프로그램을 관리할 수 있는 미래형 엑스스케일 시스템을 계획하고 있습니다.
여러분이 예상하는 바와 같이, 현재의 슈퍼 컴퓨팅 시스템은 더 전통적인 공학, 지구 과학, 에너지 과학, 재료 및 물리 응용 프로그램을 실행하고 있습니다.
이 사이트에서는 생물학, 생체역학, 생화학 및 심층 학습 응용 프로그램에 대한 수요가 증가하고 있습니다. 새로운 애플리케이션에는 연산 가속기가 필요하며, 이 사이트는 엔지니어와 과학자들의 활용도와 생산성을 높이기 위해 NVIDIA® Tesla® P100 GPU에 투자했습니다. 도쿄대 정보기술센터(ITC)가 슈퍼컴퓨터에 연산 가속기를 채택한 것은 이번이 처음입니다.
그림 1을 보시면, Reedbush는 CPU 노드만으로 구성된 Reedbush-U와 , 컴퓨터 가속기로 탑재된 2개의 GPU가 있는 노드로 구성된 Reedbush-H, 4 개의 GPU가 설치된 노드로 구성된 Reedbush-L으로 되어있는 슈퍼컴퓨터입니다. 이 하위 시스템들은 독립적으로도 작동할 수 있습니다.
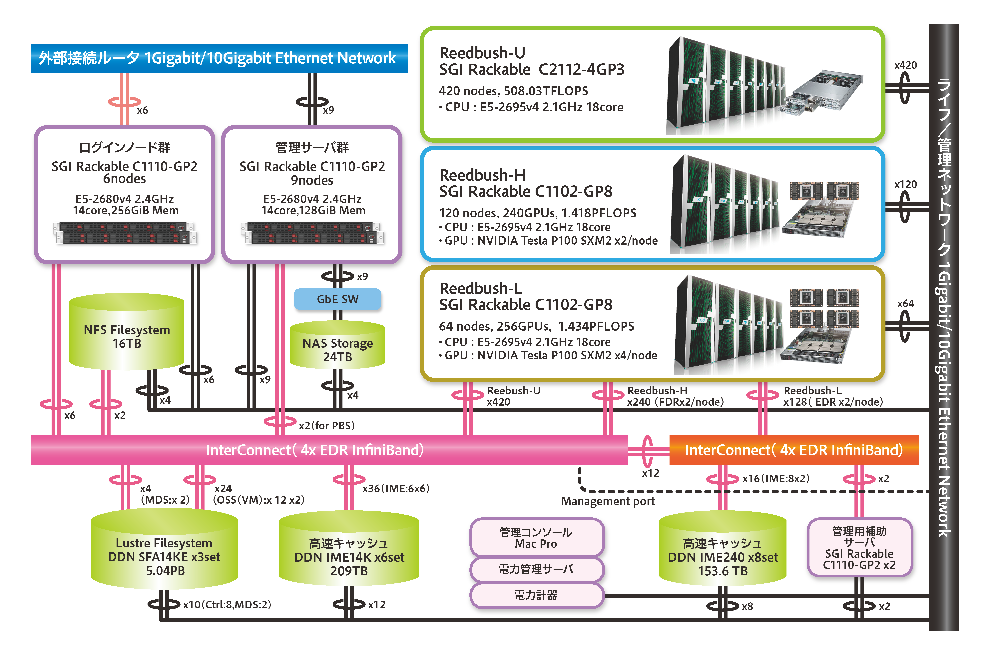
그림 1
도쿄대학교의 ITC는 3가지 시스템의 모든 계산 기능을 통해 강력하고 복원력이 뛰어나고 전력 효율적인 환경을 제공하여 사용자가 설계 및 과학적 발견을 완료 할 수 있도록하는 솔루션이 필요했습니다.
Hewlett-Packard Enterprise (HPE)와 알테어는 Reedbush 슈퍼 컴퓨터에서 Altair PBS Professional과 함께 NVIDIA 데이터 센터 GPU 관리자 (DCGM)를 사용하여 GPU 모니터링을 통합하는 프로젝트를 공동으로 수행했습니다.
HPE는 알테어와 협력하여 PBS Professional 내에서 GPU 모니터링 및 워크로드 전력 관리 기능을 개발했습니다. 이 솔루션에는 활성 상태 모니터링, 진단, 시스템 유효성 검사, 정책, 전원 및 클럭 관리, 그룹 구성 및 회계를 포함하여 각 호스트 시스템에서 다양한 기능을 수행하는 오버 헤드가 낮은 도구 모음인 NVIDIA DCGM이 포함되어 있습니다.
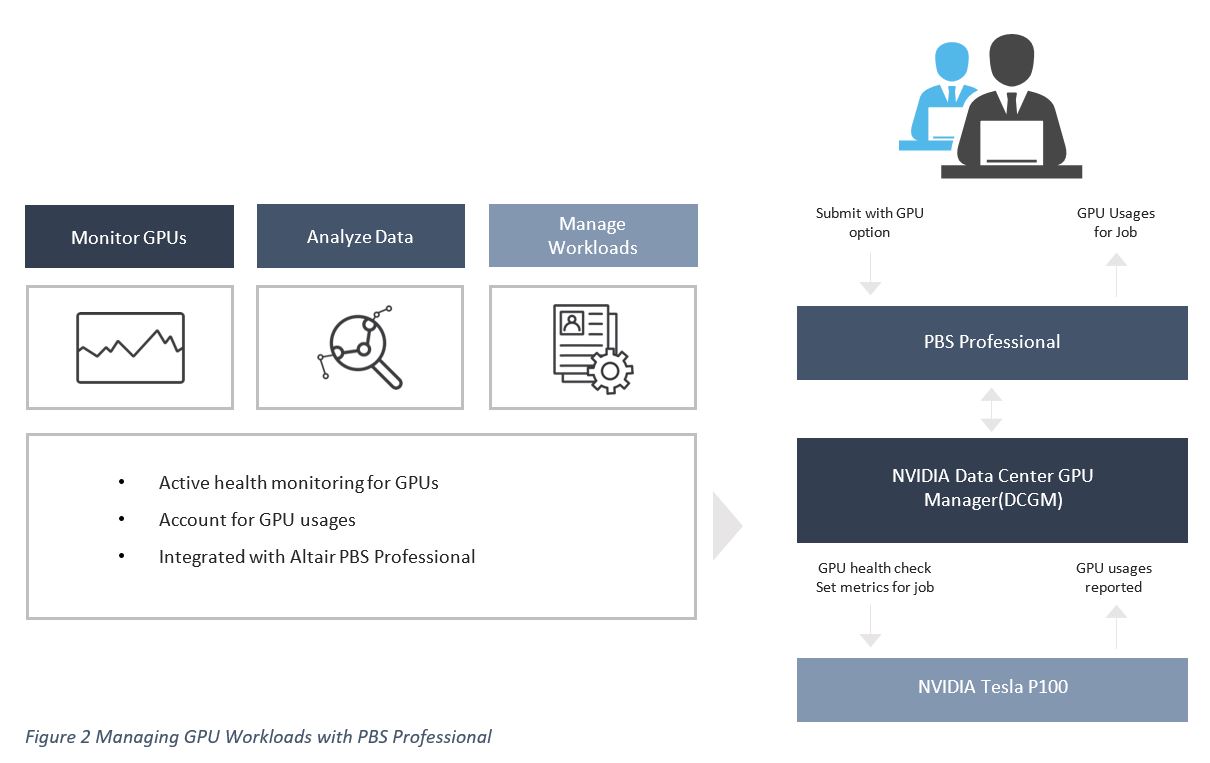
PBS Professional NVIDIA DCGM 통합
PBS Professional 및 NVIDIA DCGM 통합에는 다음과 같은 이점과 기능이 포함됩니다.
– 시스템 탄력성 향상
– 노드 상태 자동 모니터링
– GPU에서 자동 진단 실행
– GPU 오류로 인한 작업 실패의 위험 감소
– GPU 환경 오류가있는 노드에서 작업 실행 방지
– GPU 로드 및 상태 모니터링을 통한 작업 스케줄링 최적화
– 사용자가 작업이 어떻게 영향을 받는지 이해할 수 있도록 노드 건강 정보 제공
– 향후 계획을 위한 GPU 사용 기록
통합은 아래의 그림 3과 그림 4에서 볼 수 있듯이 몇 가지 PBS Professional 플러그인 이벤트 (a.k.a. hooks)를 사용합니다. 이 기사의 모든 플러그인/후크 이벤트에 대해서는 따로 말씀드리지 않으며, PBS Professional Administrator Guide를 검토하는 것이 좋습니다.
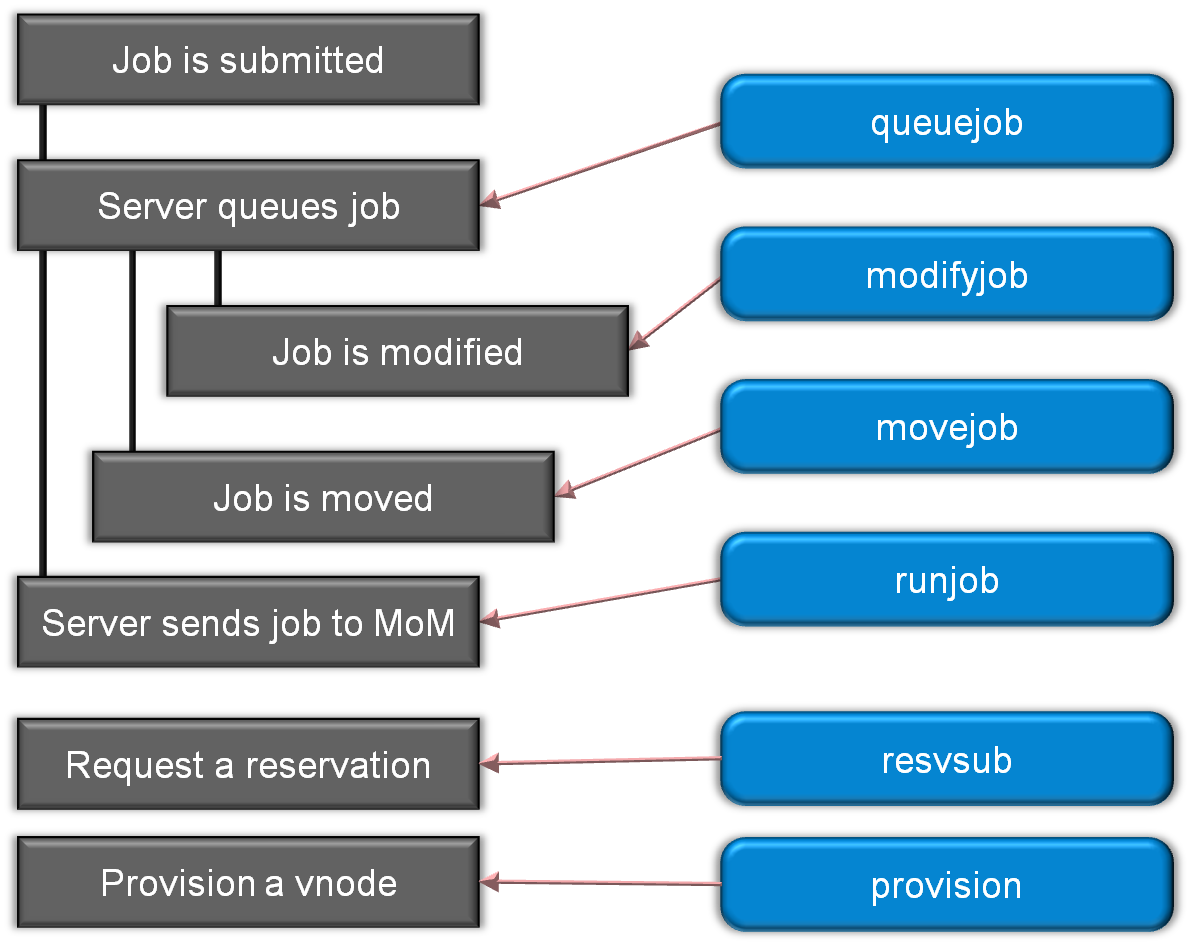
그림 3 승인 제어 및 관리 플러그인
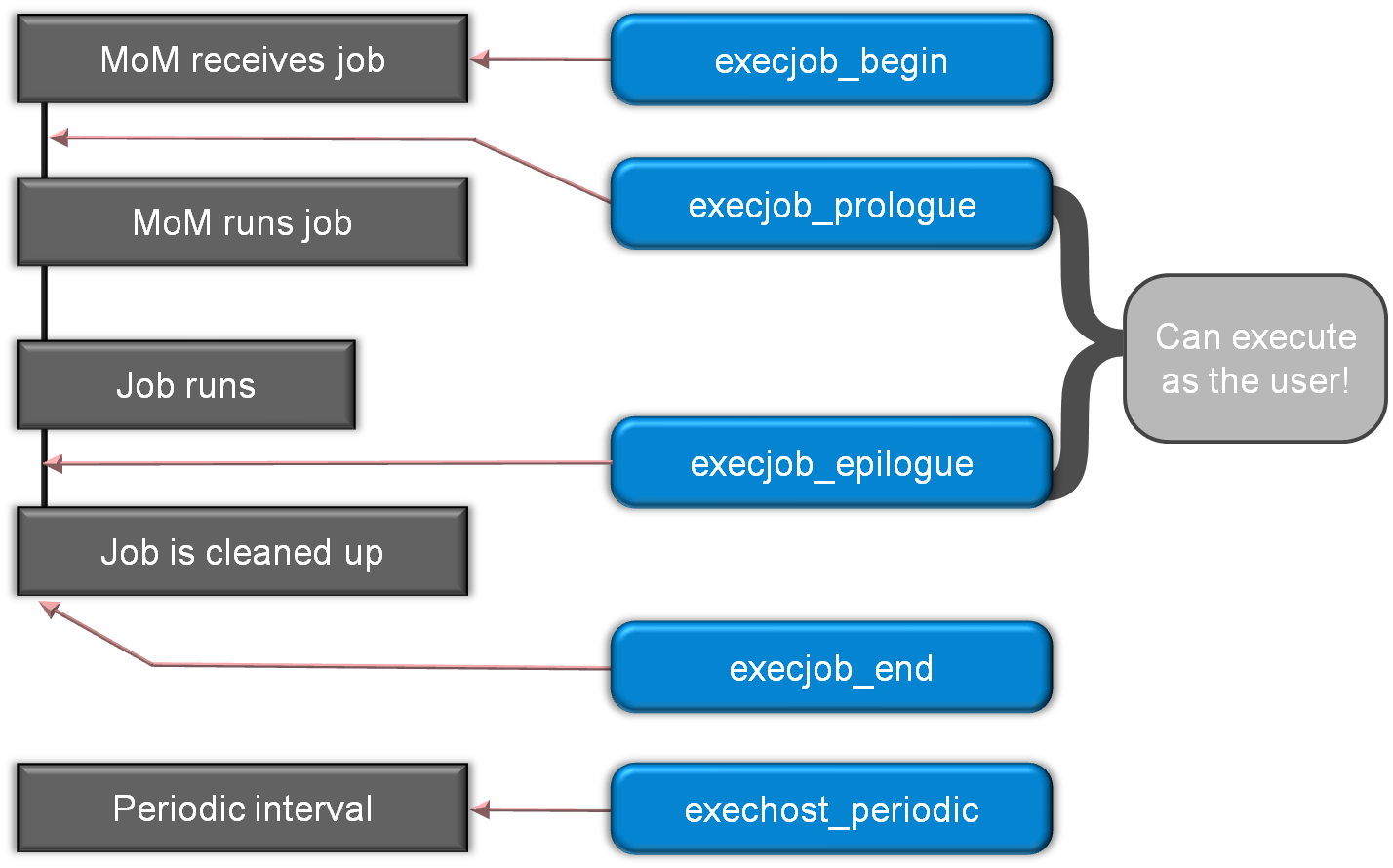
그림 4 작업 실행 플러그인
후크(hooks)에는 약간의 배경이 있습니다. 후크는 작업의 라이프 사이클에서 특정 지점에서 실행할 수있는 사용자 지정 실행 파일입니다. 각 유형의 이벤트에는 해당하는 후크가 있으며 사용자 워크플로우의 동작을 허용, 거부 또는 수정할 수 있습니다. 이 통합은 execjob_begin, execjob_epilogue, execjob_end 및 exechost_periodic 후크 이벤트를 사용합니다.
시스템/GPU 유효성 검사 및 상태 검사 수행
통합은 NVIDIA DCGM 상태 점검을 호출해 통과, 경고 또는 고장일 수 있는 결과를 분석합니다. 이상적으로 우리는 모든 것이 통과되기를 원하지만, 우리가 알다시피, 시스템은 문제를 일으킬 수 있습니다. 통합에서 경고 및 오류를 감지하면 다음 이벤트가 트리거됩니다.
1. 오프라인 노드; 더 이상 새 작업을 수락할 수 없습니다.
2. 데몬 로그에 오류를 기록합니다.
3. 노드에 시간이 표시된 주석을 설정하십시오.
4. 사용자의 ER 파일에 오류를 기록합니다.
경고와 실패의 차이점은 경고가 있을 경우 통합으로 작업이 계속 실행될 수 있다는 것입니다. 하지만 실패의 경우 통합을 통해 작업을 해야하며 스케줄러가 정상 노드를 식별할 수 있게 됩니다.
통합하면 상태 점검 외에도 소프트웨어 배포 테스트, 스트레스 테스트 및 하드웨어 문제를 포함하여 NVIDIA DCGM에서 지원하는 진단 작업도 수행할 수 있습니다. 통합에서 진단 점검에 실패하면 다음 이벤트가 트리거됩니다.
1. 오프라인 노드; 더 이상 새 작업을 수락할 수 없습니다.
2. 데몬 로그에 오류를 기록합니다.
3. 노드에 시간이 표시된 주석을 설정하십시오.
4. 사용자의 ER 파일에 오류를 기록합니다.
작업별 GPU 사용량
시스템과 GPU가 초기 테스트를 통과하면 작업이 GPU 사용량을 추적하기 시작하여 작업이 종료될 때 PBS Professional 계정 로그에 기록될 수 있습니다.
결과
통합이 제대로 작동하는지 확인하기 위해 이 사이트는 PBS Professional에 수백 개의 HPL(High-Performance LINPACK)과 GPU 작업을 제출하여 상태 점검 및 GPU 계산을 실행했습니다.
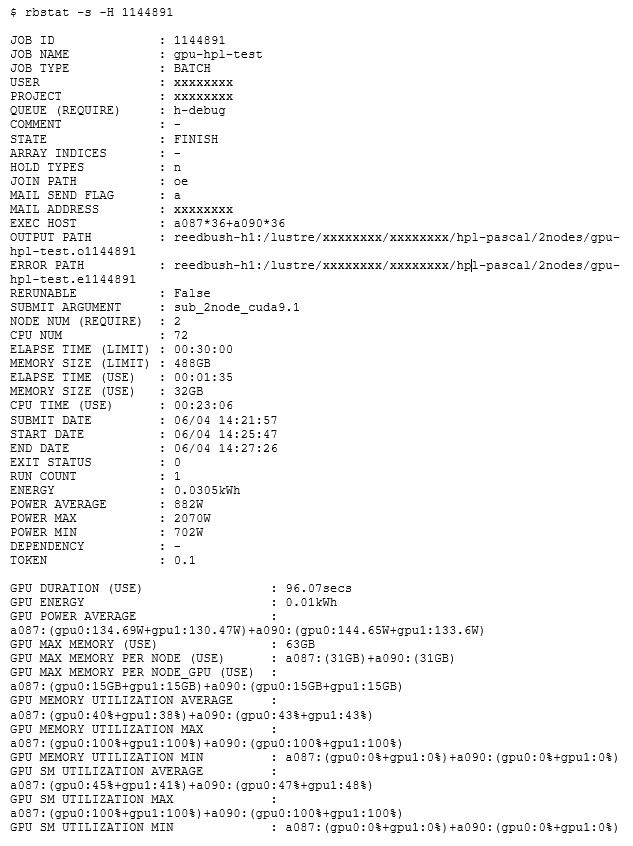
아래는 완성 된 HPL 작업의 GPU 사용법 중 하나를 설명하는 qstat -xf 스니펫입니다.

아시는 바와 같이 PBS Professional은 많은 정보를 기록합니다. (때로는 너무 많은 정보를 기록할 때도 있습니다.) ITC는 특정 작업 세부 정보를 추출하고 사용자와 관리자를 위해 출력을 단순화하기 위해 rbstat이라는 사용자 지정 명령을 개발했습니다.
PBS Professional과 NVIDIA DCGM 통합은 ITC의 인프라에서 사용자의 설계 및 과학적 발견이 완료될 수 있도록 하는 데 중요합니다. 또한 통합을 통해 관리자와 사용자는 향후 조달에 사용할 수 있는 지식인 시스템 및 GPU의 활용에 대한 더 많은 통찰력을 얻을 수 있습니다.
이 예에서는 NVIDIA DCGM과 통합되는 측면에 초점을 맞추었지만, 동일한 기능은 하드웨어 및 OS에 구애받지 않으며 모든 시스템에서 사용할 수 있습니다. 이 예에서 사이트를 맞춤 설정하고 사용자의 진화하는 요구 사항 및 사용자가 사이트 별 측정 항목에 대한 사용자의 보고 요구 사항과 진화하는 요구 사항을 충족하기 위해 수행할 수 있는 작업에 대한 몇 가지 아이디어를 얻으셨기를 바랍니다.
자세한 내용은 (여기)에서 확인하세요.
