
래피드마이너 셀프스터디 4편 : 전처리 (2) – 데이터 스케일링(Scaling)
데이터의 용량이 커서 분할 저장된 경우,데이터가 각각 수집된 경우 등등여러 개로 분할된 데이터를 합치는 방법과 데이터의 행과 열을 바꾸는 방법을 래피드마이너로 실습해 보겠습니다!
저번 포스팅 바로가기 : https://blog.altair.co.kr/rapidminer-self-study-3-data-integration
수치형 데이터 전처리 기법 중 하나인
데이터 스케일링 방법을 알아보고,
대표적인 스케일링 기법(표준화, 최소-최대 정규화)을
래피드마이너로 실습해 보겠습니다!!
스케일링 (Scaling)
– 표준화
– 정규화
▶ 데이터 스케일링(Data Scaling)이란?
서로 다른 변수를 비교할 수 있게끔 데이터 값의 범위를 비례적으로 조정하는 작업을 의미합니다.
데이터 범위의 차이가 클 경우 알고리즘 학습 과정에서 0으로 수렴하거나 ∞으로 발산하는 문제가 발생할 수 있기 때문에 데이터 스케일링은 전처리 작업에서 중요한 과정입니다.
* 모든 데이터에 적용하는 것이 아닌, (수치형) 속성 값 범위에 차이가 있는 경우에만 진행합니다!
▶ 스케일링을 하는 이유
머신러닝 모델의 성능 향상(특정 데이터의 편향성 및 왜곡 방지)
거리 기반 알고리즘(K-NN, SVM 등)은 표준화 필수
스케일링(표준화) 후 특정 범위를 벗어나는 데이터를 확인하여 이상치 판별에 사용 가능
시각화 및 해석에 용이
* 트리 기반 알고리즘(Decision Tree, Random Forest 등)의 경우 값의 스케일에 영향을 받지 않으므로 표준화할 필요가 없습니다!
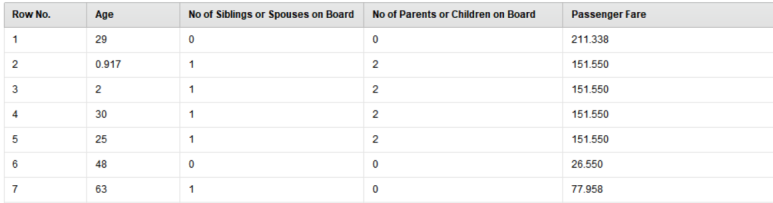
타이타닉 (수치형) 데이터로 예를 들어보겠습니다.
– Age(나이) → n 세
– No of Siblings or Spouses on Board(형제+배우자 수) → n 명
– No of Parents or Children on Board(부모+자식 수) → n 명
– Passenger Fare(티켓 금액) → n $
이와 같이 변수별로 사용하는 단위가 서로 다른 것을 확인할 수 있습니다.

컴퓨터는 우리와 같이 몇 세, 몇 명, 몇 달러 등의 의미로 이해하지 못하고 숫자 그 자체로만 받아들여 계산합니다.
나이, 형제 및 배우자 수, 부모 및 자식 수, 티켓 금액과 같은 독립 변수들이 종속 변수를 예측하는 데 있어 함께 고려되어야 하지만, 머신러닝 모델은 단지 값의 범위가 큰 Passenger Fare(티켓 금액)에 중점을 두고 판단하게 될 것입니다.
따라서 데이터 범위 차이의 왜곡을 방지하고 데이터 값이 머신러닝 모델에 동일한 영향을 미칠 수 있도록 조정해야 합니다!
▶ 스케일링의 종류
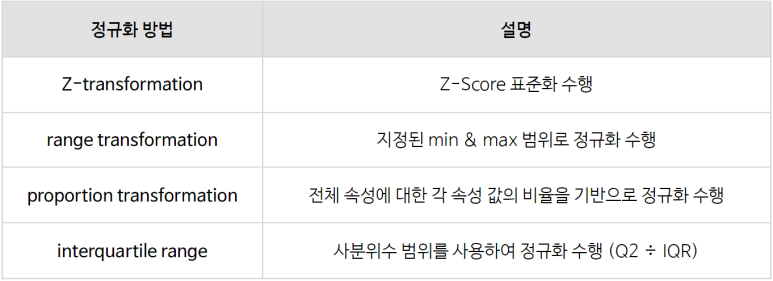
① 표준화(Standardization)
: 각 개체들이 평균을 기준으로 얼마나 떨어져 있는지를 나타내는 값으로 변환하는 방법입니다.
※ Z-Score(Z-점수)
: 데이터의 모든 값에서 데이터의 평균을 뺀 다음 표준 편차로 나누어
평균이 0이고 표준편차가 1인 정규 분포로 변환하는 방법입니다.
데이터의 원래 분포를 유지할 수 있고, 이상값의 영향을 덜 받습니다.
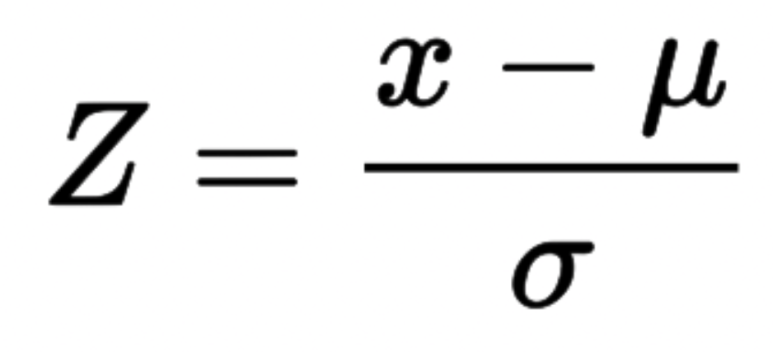
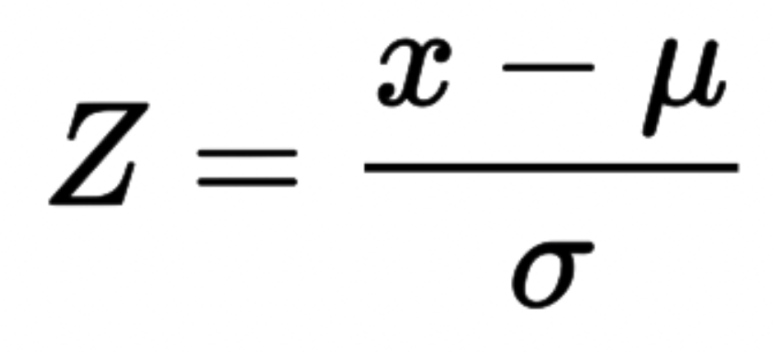
Z-Score 공식
* 데이터의 원래 분포가 정규분포가 아닌 경우 기존 데이터의 특성을 잃어버릴 수 있음.
② 정규화(Normalization)
: 데이터를 특정 범위로 변환하여 데이터를 조정하는 방법입니다.
데이터 내에서 특정 개체가 가지는 위치를 파악하고 비교할 때 유용합니다.
※ Min-Max Normalization(최소-최대 정규화)
: 데이터의 범위(분포)를 0과 1 사이로 변환하는 방법입니다.
데이터에서 가장 작은 값이 0이 되고, 가장 큰 값이 1이 되어
모든 데이터가 0 ~1사이의 범위를 가지게 됩니다.
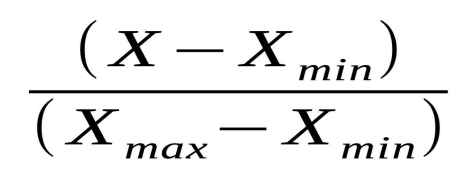

Min-Max 정규화 공식
* 최소-최대 정규화는 이상치에 민감하므로 정규화 전 이상치 제거 및 변환을 추천함.
▶ 표준화와 정규화 중 어떤 기법을 선택해야 하는가?
⇒ 스케일링은 위에서 소개한 방법 외에도 다양한 기법들이 존재합니다.
⇒ 보통 Z-Score와 Min-Max 정규화를 주로 사용하지만 무조건적인 정답은 없습니다!!!
① 데이터의 특성에 따라 스케일링 기법 선택
② 각 스케일링 기법마다 모델의 성능을 비교한 후 선택
③ 딥러닝 모델의 경우 활성화 함수의 처리 범위를 함께 고려하여 선택
● Normalize
래피드마이너에서는 스케일링을 Normalize 오퍼레이터로 구현할 수 있습니다.
하나의 오퍼레이터이지만, 파라미터 설정을 통해 표준화 및 다양한 정규화 방법을 지정할 수 있습니다.
먼저, 타이타닉 데이터에서 스케일링이 필요해 보이는 변수를 확인해 보겠습니다.
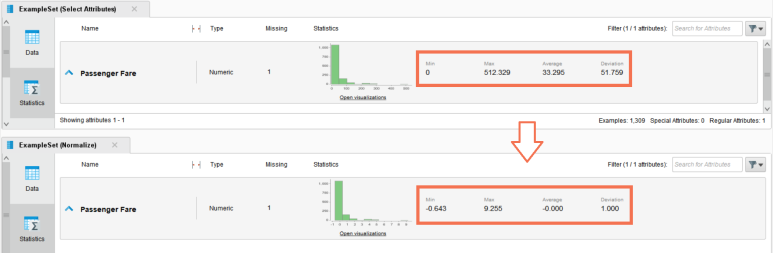
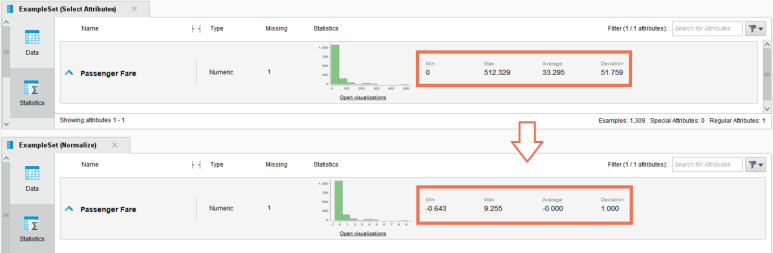
Passenger Fare(티켓 금액)의 통계값을 확인했을 때, 최솟값이 0$, 최댓값이 512.329$로 값의 범위가 꽤 차이나고 있음을 알 수 있습니다.
Passenger Fare(티켓 금액)는 평균 금액인 33.295$로 부터 51.759$ 정도 흩어져서 분포하고 있으며, 이는 히스토그램으로도 함께 확인할 수 있습니다.


Retrieve Titanic 과 Select Attributes 오퍼레이터를 연결하여 타이타닉 데이터에서 Passenger Fare(티켓 금액) 변수만 선택하고, 표준화를 위한 Normalize 오퍼레이터를 exa 포트(=예제)로 연결해 줍니다.
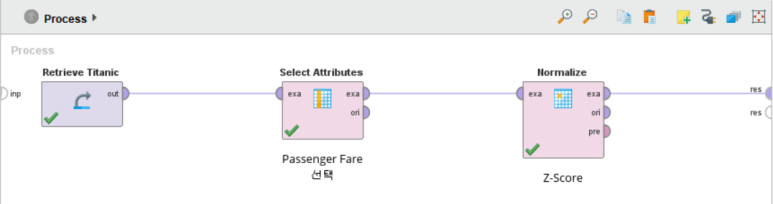
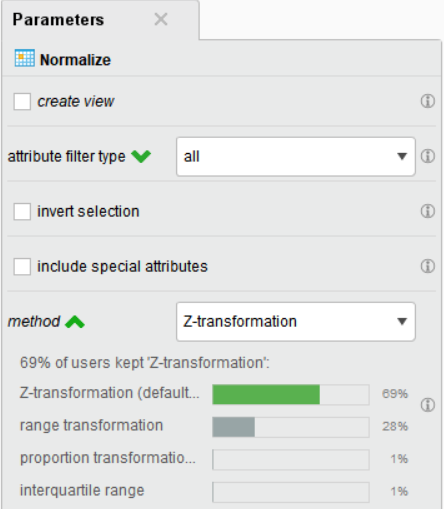
Normalize 오퍼레이터의 파라미터를 지정해 줍니다.
• create view : 데이터의 변환된 모습만 확인하고 적용하지는 않음
• attribute filter type : 변수 선택 방법
• invert selection : 선택한 변수의 반대로 지정
• include special attributes : id, weight, label 등과 같이 특정 역할로 지정된 변수 포함 여부
• method : 스케일링 방법 선택
Z-Score 표준화를 적용하기 위해 method를 Z-transformation으로 지정하고 실행합니다.
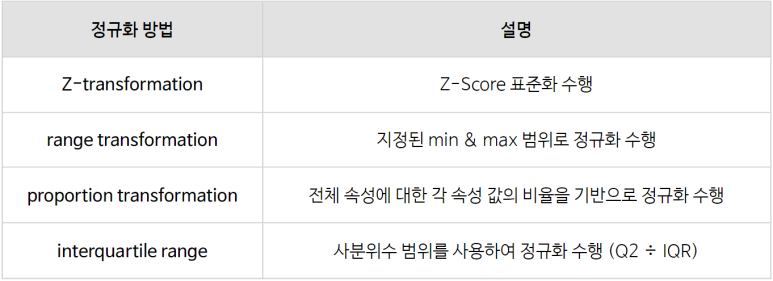
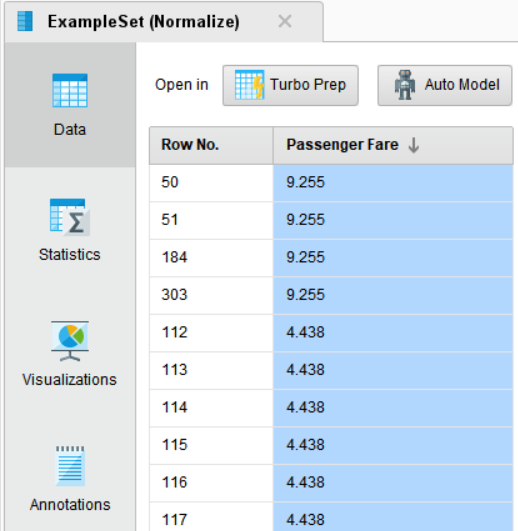
실행 결과, 실제 데이터 값도 바꼈으며 분포를 나타내는 통계량 역시 표준화된 모습을 보이고 있습니다!
데이터의 최솟값, 최댓값, 평균값, 분산값과 히스토그램의 x축 범위가 축소 조정되었지만,
데이터의 전체적인 분포는 그대로 유지되고 있습니다.

일반적으로 Z-Score를 사용할 때, ±3 이 넘어가는 범위의 데이터를 이상치로 간주하기도 합니다.
표준화 결과 양수 값 중 3보다 크게 나타나는 값이 일부 있었습니다.
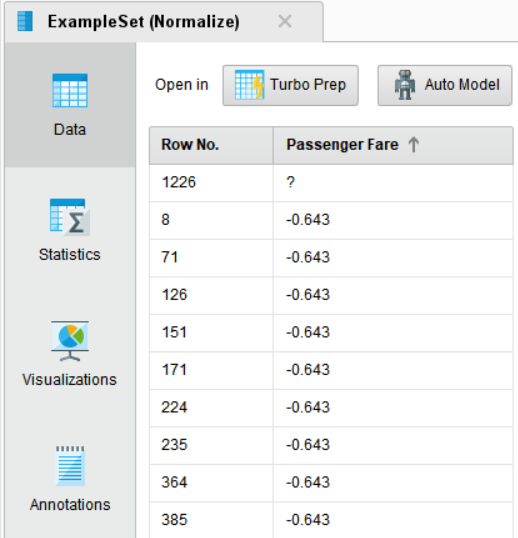
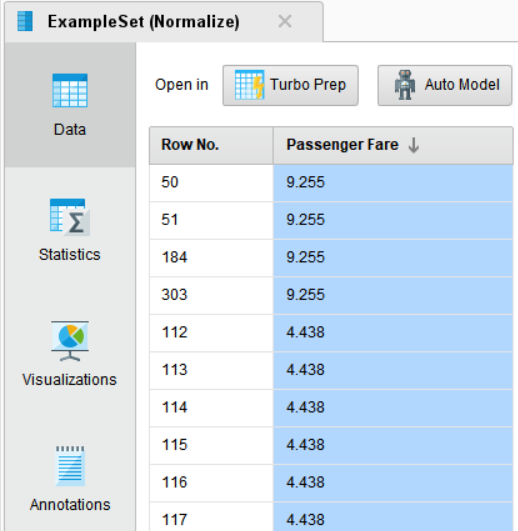
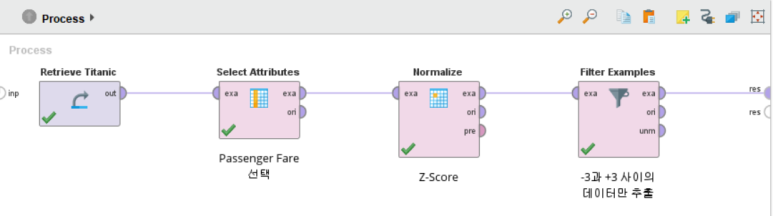
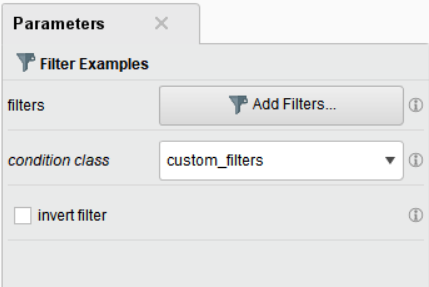
Filter Examples 오퍼레이터를 추가하여 표준화된 Passenger Fare(티켓 금액)값에서 ±3 이내의 데이터만 추출하도록 하겠습니다.
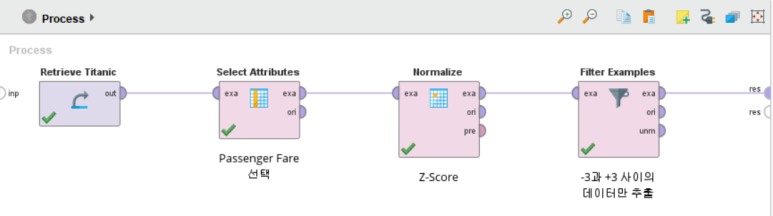
Filter Examples 오퍼레이터의 파라미터인 Add Filters를 클릭하여 데이터 필터링 조건을 지정합니다.
• Match all : 여러 조건을 함께 고려하는 AND의 개념
• Match any : 각각의 조건을 고려하는 OR의 개념
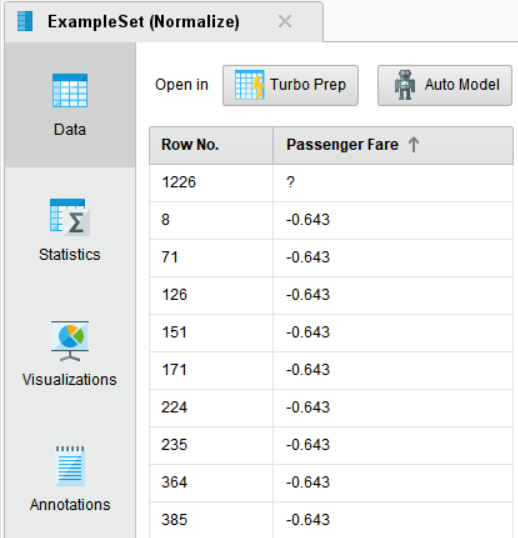
(Passenger Fare ≤3) AND (Passenger Fare ≥ -3) 으로
-3 ~ +3 사이에 해당하는 데이터만 추출되도록 설정하였습니다.
(invert filter을 체크하면 -3 ~ +3 범위의 외의 데이터들이 출력됩니다.)
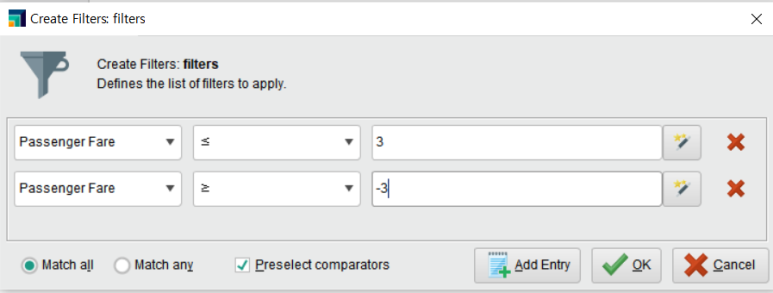

필터링 결과 ±3 이내의 표준화된 데이터로 구성되었습니다.

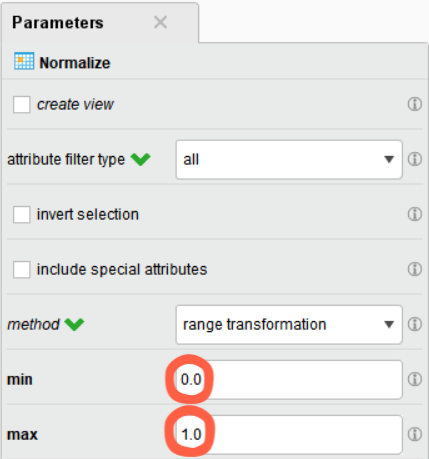
이번에는, Normalize 오퍼레이터의 method 파라미터를 range transformation으로 변경하여 최소-최대 정규화를 수행해 보겠습니다.
오퍼레이터 연결 방법은 동일합니다.
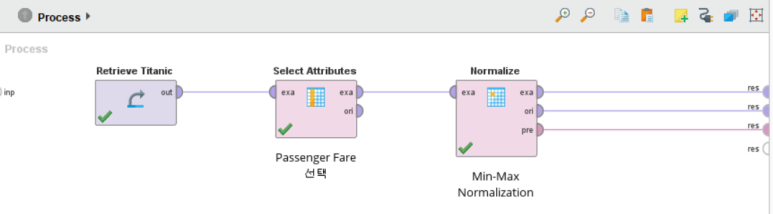

range transformation으로 지정하면 min, max를 지정하는 파라미터가 등장합니다.
min을 0, max를 1로 지정하면 최소-최대 정규화가 가능합니다.

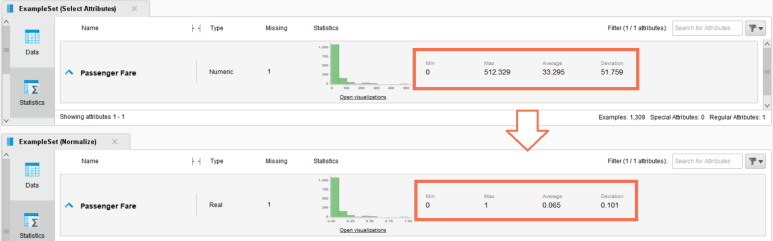
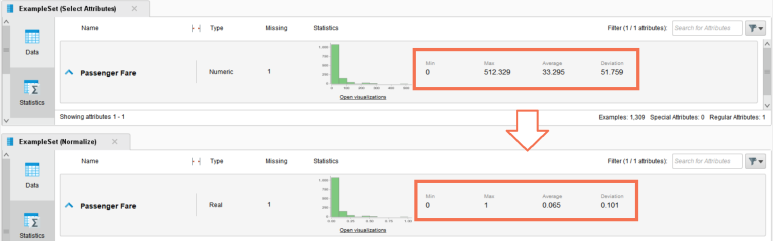
실행 결과, 실제 데이터 값도 바꼈으며 분포를 나타내는 통계량 역시 정규화된 모습을 보이고 있습니다!
데이터의 최솟값이 0, 최댓값이 1로 최소-최대 정규화가 잘 적용된 것을 확인할 수 있습니다.
0 ~ 512 범위의 값보다 0 ~ 1 범위의 값이 알고리즘에 덜 편향적인 영향을 줄 수 있을 것 같습니다.!

만약, 정규화 이전의 값으로 되돌리고 싶은 경우는 어떻게 해야 할까요?
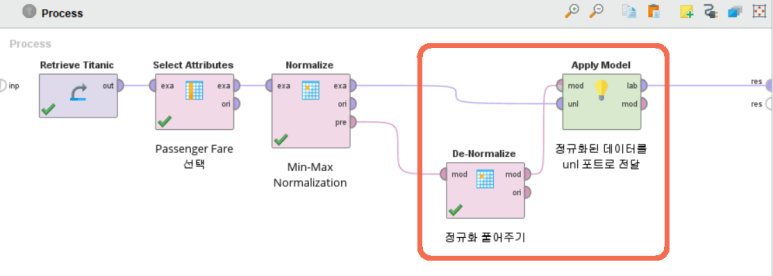
이를 위해서 De-Normalize 오퍼레이터가 존재합니다!
정규화된 데이터에 정규화 모델을 이용하여 De-Normalize 오퍼레이터를 적용해주면 됩니다.
반정규화를 하기 위해선 정규화했던 정보가 필요합니다.
최소-최대 정규화의 경우, 기존 데이터의 최솟값과 최댓값 등을 알아야 할 것입니다.
이러한 통계 정보는 지금까지 사용한 Normalize 오퍼레이터의 pre 포트로 출력할 수 있습니다.
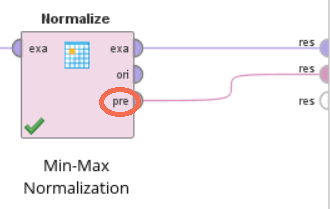

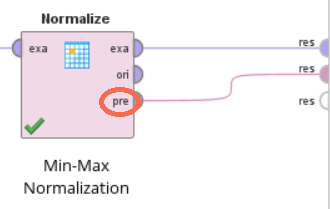

Normalize 오퍼레이터의 pre 포트를 De-Normalize 오퍼레이터의 mod 포트에 연결하여 기존 데이터의 통계 정보를 전달해주고, Apply Model 오퍼레이터로 반정규화를 수행합니다.
이 때, 정규화된 데이터를 Apply Model 오퍼레이터의 unl 포트로 전달해 줍니다.

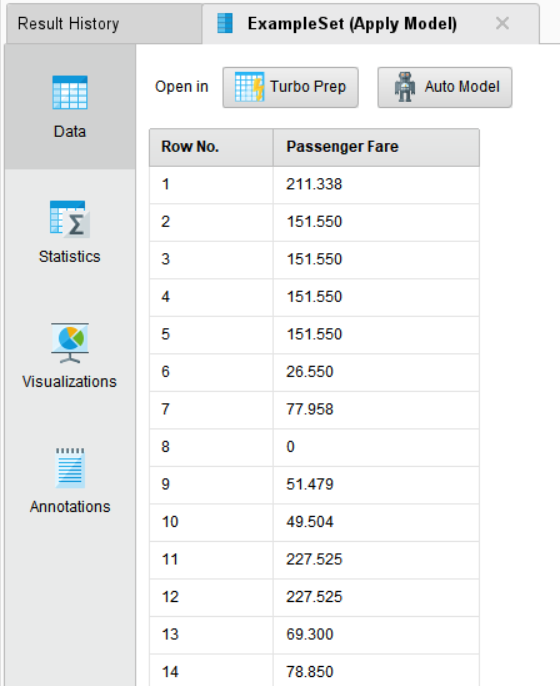
출력 결과, Passenger Fare 데이터의 원래 모습 그대로 변환되었습니다.
기존 데이터의 통계값을 참고했기 때문에 그대로 복원할 수 있는 것입니다!
< Z-Score 표준화 – 파이썬으로 구현하기>
<Min-Max 정규화 – 파이썬으로 구현하기>
test_inv_mm = minmax.inverse_transform(test_scaled_mm)
다음 포스팅을 기대해주세요!
Altair RapidMiner 플랫폼은 데이터 수집부터 모델링, 운영, 시각화에 이르기까지 전체적인 엔드투엔드 솔루션을 제공합니다.
고객들이 LLM의 강력한 기능을 안전하고 안정적으로 활용할 수 있도록 생성형 AI를 솔루션에 통합했으며, Altair RapidMiner는 고객이 생성형 AI 모델을 쉽게 접근하고 구축할 수 있도록 지원합니다.
더 많은 정보를 원하시면 알테어 래피드마이너(Altair RapidMiner)-바로가기(클릭) 페이지를 방문해 주세요.

![[RapidMiner 래피드마이너 셀프 스터디] #3 전처리 (1) 데이터 병합 & 행열 전환](https://blog.altair.co.kr/wp-content/uploads/사진자료-알테어-래피드마이너-2023-500x383.jpg)
![[RapidMiner 래피드마이너 셀프 스터디] #2-1 시각화와 그룹핑으로 데이터 탐색하기](https://blog.altair.co.kr/wp-content/uploads/Rapidminer-로고-1-500x383.png)