
래피드마이너 셀프스터디 2편 : 시각화와 그룹핑으로 데이터 탐색하기
아직 래피드마이너 다운로드를 받지 않으신 분들은 해당 영상 및 하단의 링크를 참조해주세요! https://www.youtube.com/watch?v=_NNKhBoLhRw
래피드마이너로 데이터의 기본적인 통계값을 탐색해보는 과정을 실습해보겠습니다.
· 단일 데이터 탐색
– 품질 확인
– 기초 통계량
– 시각화
· 변수 조합 및 그룹핑
– 상관관계
– 그룹핑 (집계표 & 피벗 테이블)
– 데이터 작성
데이터 탐색을 통해 데이터를 명확하게 이해하고 데이터 분석에 대한 새로운 발견 및 가설 개발이 가능합니다.
데이터 소개 & 로딩
– 상품 배송 추적 데이터 (by Kaggle)
데이터 탐색하기 (1)
– 기초 통계량
– 데이터 시각화
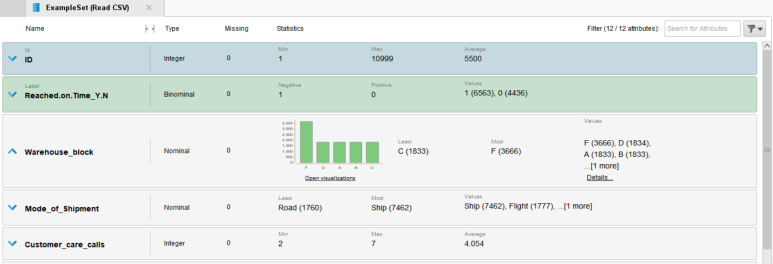
래피드마이너는 데이터 로딩만으로도 기본적인 통계값과 시각화를 함께 확인할 수 있습니다.
Read CSV 오퍼레이터로 데이터를 실행한 후, 왼쪽 Statistics를 클릭하면 컬럼별로 데이터 타입 / 결측치 개수 / 통계값이 나타납니다.
※ 범주 유형 : 절대 빈도, 백분율
※ 수치 유형 : 최솟값, 최댓값, 평균, 분산

확인하고자 하는 컬럼을 클릭하면 ∧로 확장되면서 자세한 통계를 확인할 수 있습니다.

범주형 변수인 Warehouse_block(창고)에 대한 통계값을 간단히 확인해보겠습니다.
① Values에서 Details를 클릭


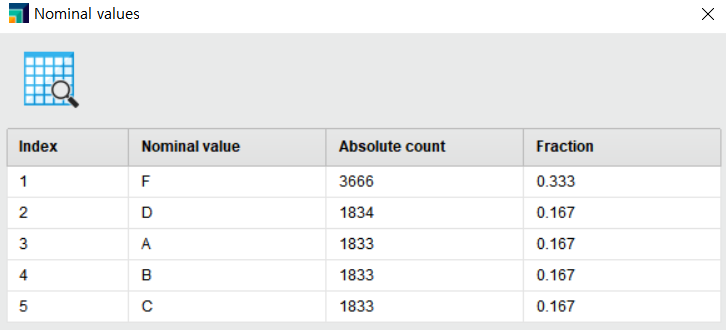

▶▶ 5개로 구분된 창고 중 F 창고에서 약 33%의 상품이 출고되었음을 알 수 있습니다.
② 그래프 아래의 Open visualizations을 클릭


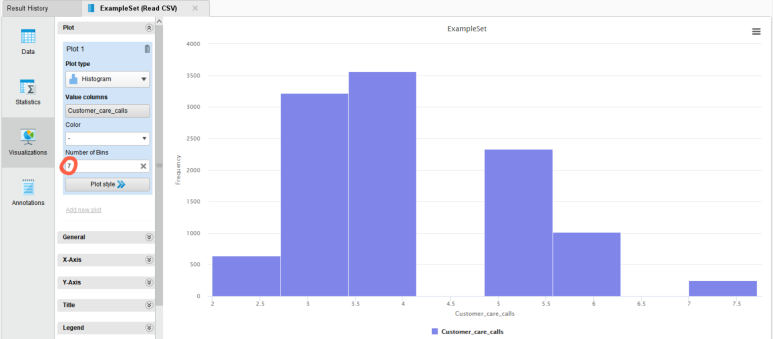
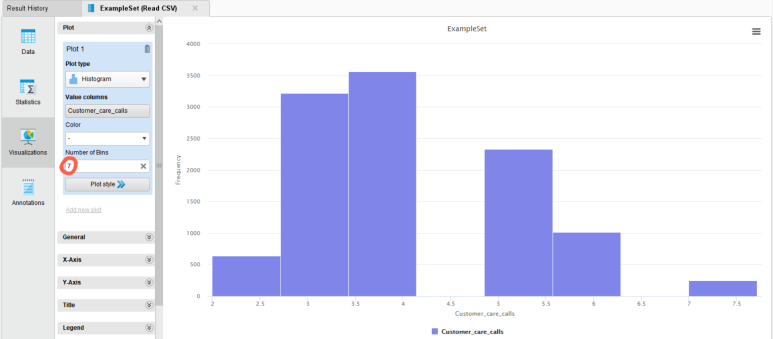
수치형 변수의 경우 기본적으로 히스토그램을 보여줍니다.
Number of Bins로 히스토그램의 구간 개수를 바꿔가며 데이터의 분포를 확인할 수 있습니다.
범주형 변수의 경우 기본적으로 막대 그래프를 보여줍니다.
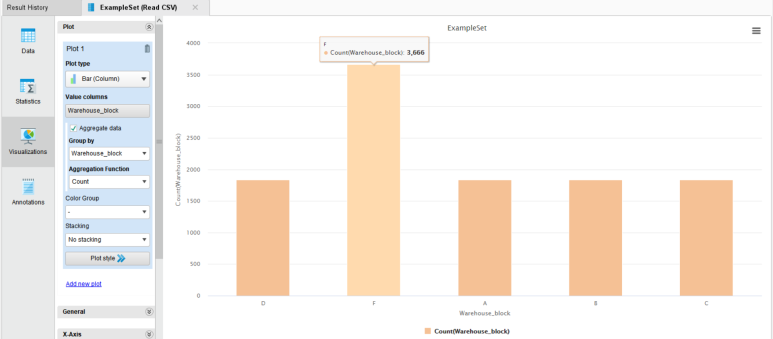

수치형 변수인 Customer care calls(배송 문의 전화 횟수)에 대한 통계값을 간단히 확인해보겠습니다.
① 그래프 옆 Min / Max / Average / Deviation 확인


▶▶ 고객들은 최소 2번에서 최대 7번까지, 평균적으로는 4번 정도 배송 문의 전화를 하는 것을 알 수 있습니다.
② 그래프 아래의 Open visualizations을 클릭
.png?type=w773)


수치형 변수의 경우 기본적으로 히스토그램을 보여줍니다.
Number of Bins로 히스토그램의 구간 개수를 바꿔가며 데이터의 분포를 확인할 수 있습니다.

래피드마이너의 Visualizations 기능은 산점도, 히트맵, 생키차트, 워드 클라우드, 맵 등과 같은 다양한 그래프 유형을 지원합니다.

Visualizations 기능을 이용하여 종속 변수인 Reached.on.Time_Y.N( 정시 배송 여부)를 도넛 차트로 시각화해보았습니다.
▶▶ 정시에 도착하지 못한 상품이 절반 이상을 차지하는 것을 확인할 수 있습니다. 고객의 만족도 향상을 위해서는 배송 프로세스를 개선할 필요가 있어 보입니다.
● Quality Measures
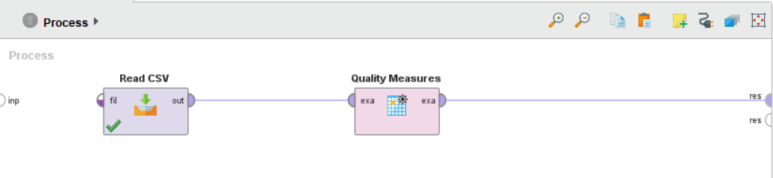
Qaulity Measures 오퍼레이터로 데이터의 품질을 확인할 수 있습니다.
데이터에 결측치가 많이 존재하거나, 범주가 한 쪽으로 치우쳐져 있는 등의 문제를 미리 확인하기 위해 사용합니다.
Read CSV 오퍼레이터의 out 포트(=출력)를 Qaulity Measures 오퍼레이터의 exa 포트(=예제)로 연결하고 출력을 res 포트(=결과)로 연결합니다.

• ID-ness : 값들이 모두 다른 정도
• Stability : 속성의 값들이 동일한 정도
• Missing : 값이 비어 있는 정도
• Text-ness : 값이 텍스트를 포함하고 있는 정도
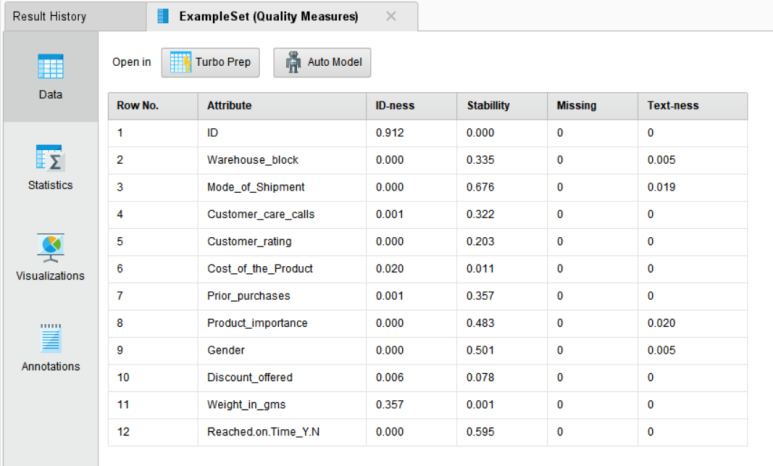
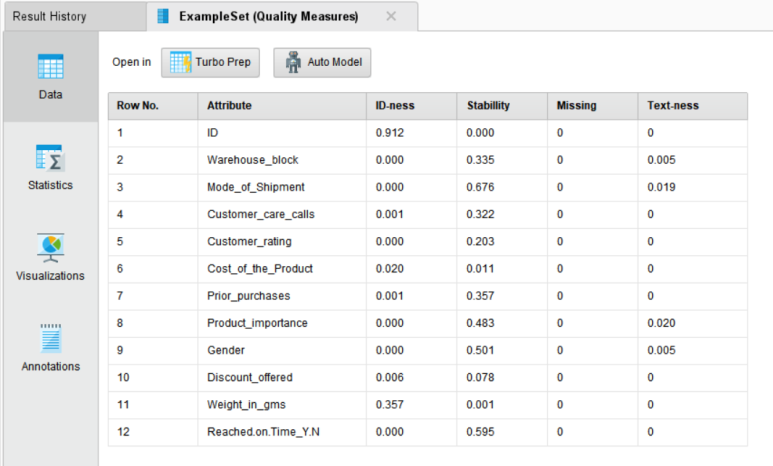

▶▶ 현재 데이터에서 ID 컬럼의 ID-ness 값이 0.912(92%)로 높아 다른 컬럼보다 ID 역할(role)로 사용하기 적합해 보입니다. Missing 값의 비율이 모두 0이므로 해당 데이터에 결측치가 없다는 것을 알 수 있습니다.
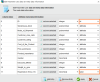
위의 과정은 데이터 유형(type)과 역할(role)을 설정하지 않은 디폴트 상태로 진행하였습니다.
지금부터는 데이터의 의미대로 자세히 탐색하기 위해 Read CSV 오퍼레이터의 파라미터를 재설정하겠습니다.


데이터가 가지고 있는 의미에 따라 유형(type)과 역할(role)을 변경해줍니다.
ex) ID 변수는 고객을 식별하기 위한 일련번호로 1~10999까지 고유한 값으로 이루어져 있습니다.
이는 고객을 구분하기 위한 숫자이므로 평균값, 분산값이 의미가 없습니다.
ex) Reached.on.Time_Y.N 변수는 0, 1 숫자값으로 표현되어 있으나,
이는 상품의 정시 도착 여부(0:Yes / 1:No)를 의미하므로 숫자의 크고 작음이 의미가 없습니다.
따라서 2개의 범주를 가지는 binominal로 변경하였습니다.
설정이 끝나면 Apply 버튼으로 변경사항을 적용시킵니다.
.png?type=w773)

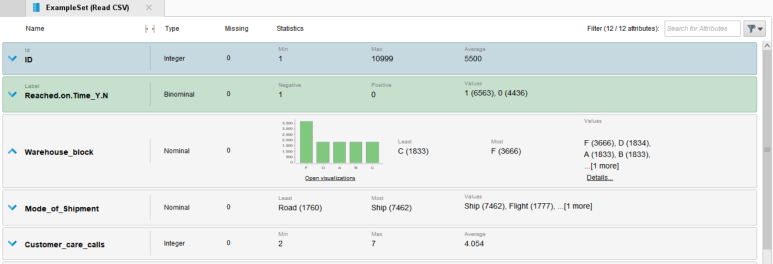
Read CSV를 다시 실행시켰을 때 Statistics에서 id, label 역할의 컬럼에 색상이 칠해진 것을 확인할 수 있습니다.

● Statistics
데이터 로딩으로 기초 통계량을 확인할 수 있지만, 이를 단독적인 Statistics 오퍼레이터로도 제공하고 있습니다.
여러 통계값을 조금 더 구체적으로 확인하고 싶을 때 사용합니다.
Read CSV 오퍼레이터의 out 포트(=출력)를 Statistics 오퍼레이터의 exa 포트(=예제)에 연결하고 sta 포트(=통계값)와 res 포트(=결과)를 연결합니다.

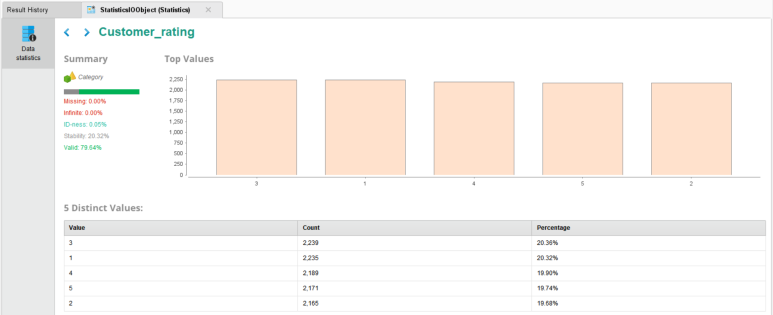
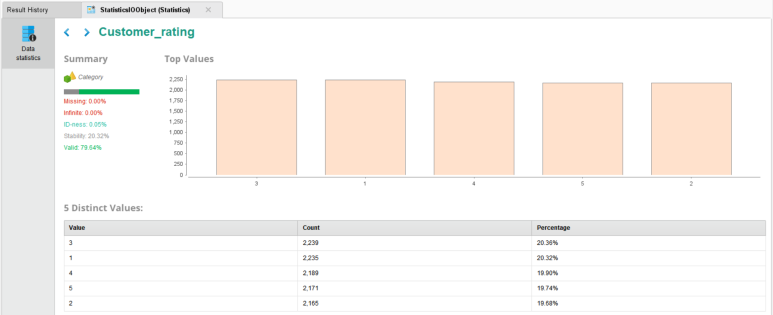

▶▶ 고객은1~5등급으로 나누어져 있으며 각 등급 모두 약 20% 정도로 비슷하게 분포되어 있습니다.

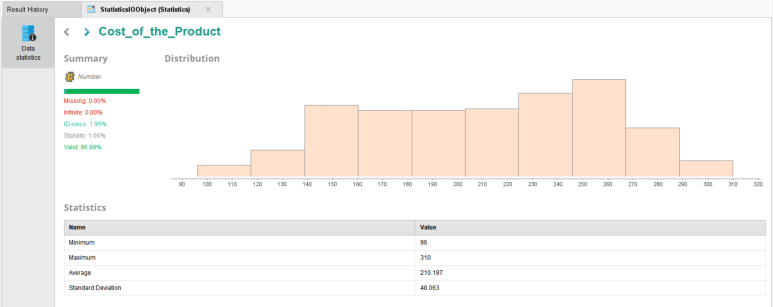

▶▶ 고객들이 구매한 상품의 최저 가격은 96$, 최고 가격은 310$, 평균 가격은 약 210.2 $인 것을 알 수 있습니다. 또한 표준편차값을 통해 상품 가격이 평균으로부터 48.06$정도 흩어져 있음을 알 수 있습니다.
![[RapidMiner 래피드마이너 셀프 스터디] 4편 : 전처리 (2) – 데이터 스케일링(Scaling)](https://blog.altair.co.kr/wp-content/uploads/사진자료-알테어-래피드마이너-2023-500x383.jpg)
![[RapidMiner 래피드마이너 셀프 스터디] #2-1 시각화와 그룹핑으로 데이터 탐색하기](https://blog.altair.co.kr/wp-content/uploads/Rapidminer-로고-1-500x383.png)