*해당 글은 래피드마이너 서포터즈의 포스팅을 바탕을 작성되었습니다.

아직 래피드마이너 다운로드를 받지 않으신 분들은 해당 영상 및 하단의 링크를 참조해주세요! https://www.youtube.com/watch?v=_NNKhBoLhRw
래피드마이너 셀프스터디 1편 : 데이터 불러오기
실습에 앞서 아래 경로에 폴더를 생성해줍니다.
C:>Users>user>Documents>RapidMiner>Local Repository
새롭게 만든 폴더에 실습 데이터와 프로세스를 저장하려고 합니다
데이터 소개
– 상품 배송 추적 데이터 (by Kaggle)
이번 실습에서 사용할 데이터는 캐글의 상품 배송 추적 데이터입니다.
Product Shipment Delivered on time or not? To Meet E-Commerce Customer Demand
이 데이터는 총 12개의 컬럼과 10,999개의 행으로 이루어져 있습니다.
고객 정보와 상품 정보가 기록되어 있으며, 이를 통해 상품 배송이 정시에 도착했는지를 예측하기 위한 데이터입니다.
|
변수명 |
유형 |
역할 |
설명 |
|
|
ID |
Integer |
독립변수 |
고객 ID |
|
|
Warehouse block |
object |
독립변수 |
A, B, C, D, E로 나누어진 창고 |
|
|
Mode of shipment |
object |
독립변수 |
선박, 항공, 도로 등의 제품 배송 방법 |
|
|
Customer care calls |
Integer |
독립변수 |
배송 조회 문의에 대한 전화 횟수 |
|
|
Customer rating |
Integer |
독립변수 |
1~5로 나누어진 고객의 등급 |
|
|
Cost of the product |
Integer |
독립변수 |
상품의 가격 ($) |
|
|
Prior purchases |
Integer |
독립변수 |
이전 구매 횟수 |
|
|
Product importance |
object |
독립변수 |
low, medium, high로 나누어진 제품의 중요도 |
|
|
Gender |
object |
독립변수 |
고객의 성별 |
|
|
Discount offered |
Integer |
독립변수 |
특정 상품에 제공된 할인 |
|
|
Weight in gm |
Integer |
독립변수 |
무게 (g) |
|
|
Reached on time_Y.N |
Integer |
종속변수 |
배송 정시 도착 여부 |
|
데이터 불러오기
우리가 주로 사용하는 데이터의 경우, Read에 포함되어 있는 오퍼레이터로 데이터를 불러옵니다. 래피드마이너는 기본적인 엑셀 데이터부터 DataBase, Google Cloud, Twitter 등 다양한 데이터 소스를 다룰 수 있습니다.
*래피드마이너에 기본적으로 사용할 수 있는 Sample data가 있습니다.
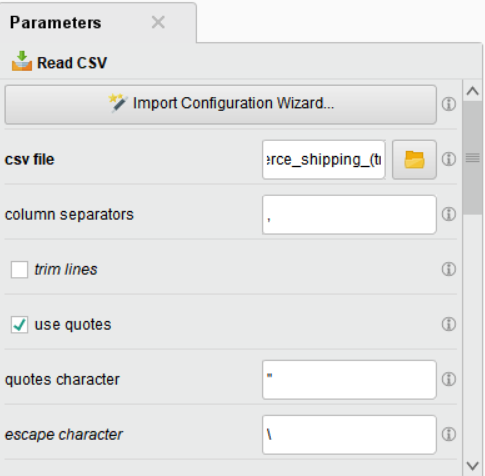
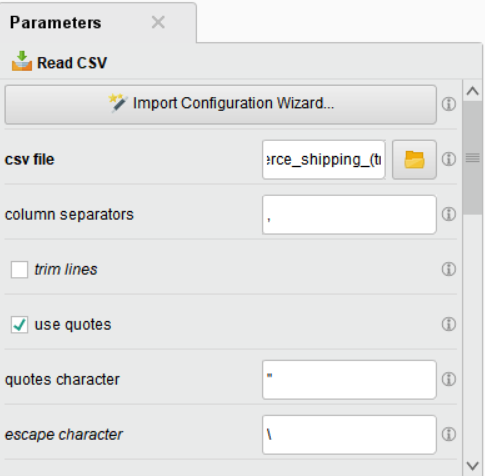
사용할 (원본) 데이터가 csv 파일이므로Read CSV오퍼레이터를 Process 패널에 가져옵니다.
이 오퍼레이터를 더블 클릭하면 다음과 같은 창이 뜹니다. 데이터를 선택하고 Next를 클릭합니다.
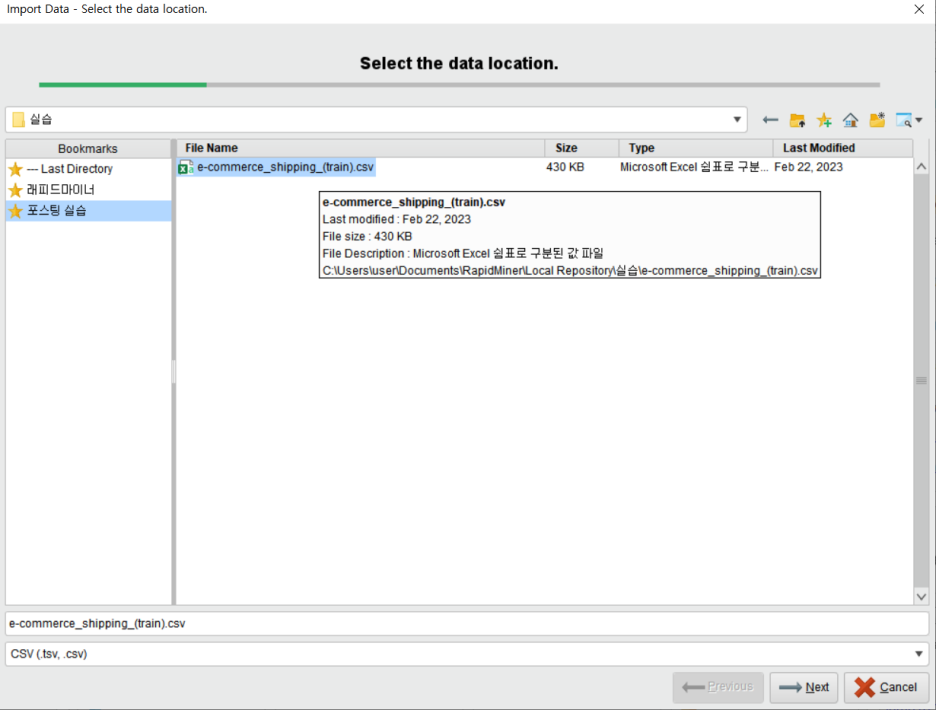
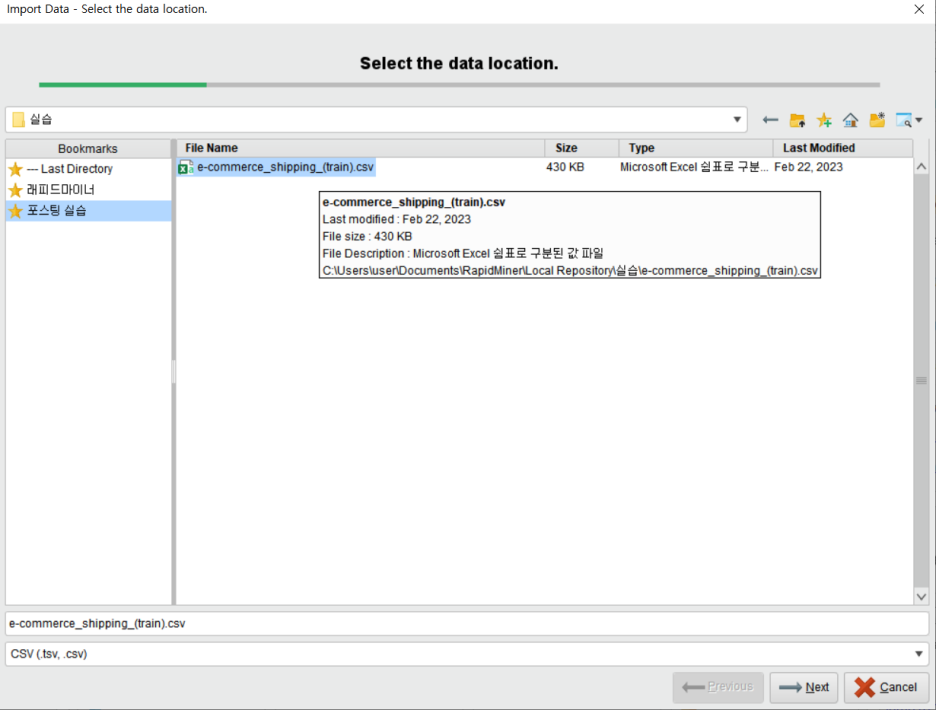
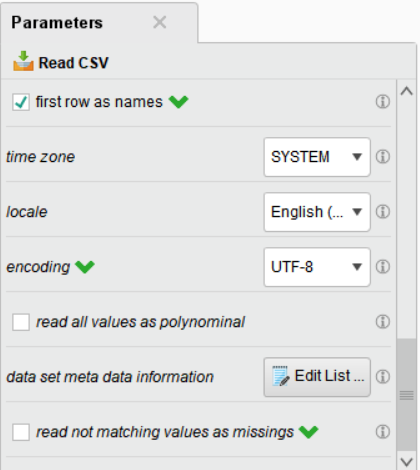
이 단계에서 꼭 확인해야 할 부분은 다음과 같습니다.
• Header Row: 컬럼명으로 사용되는 행을 지정
• Start Row: 어떤 행부터 사용할지를 지정
• Column Separator: 데이터 구분자 지정
• File Encoding: 인코딩 지정
오류없이 컬럼과 행이 잘 불러와졌는지를 확인하고
아래의 no problems의 체크가 뜨면 Next를 클릭합니다.
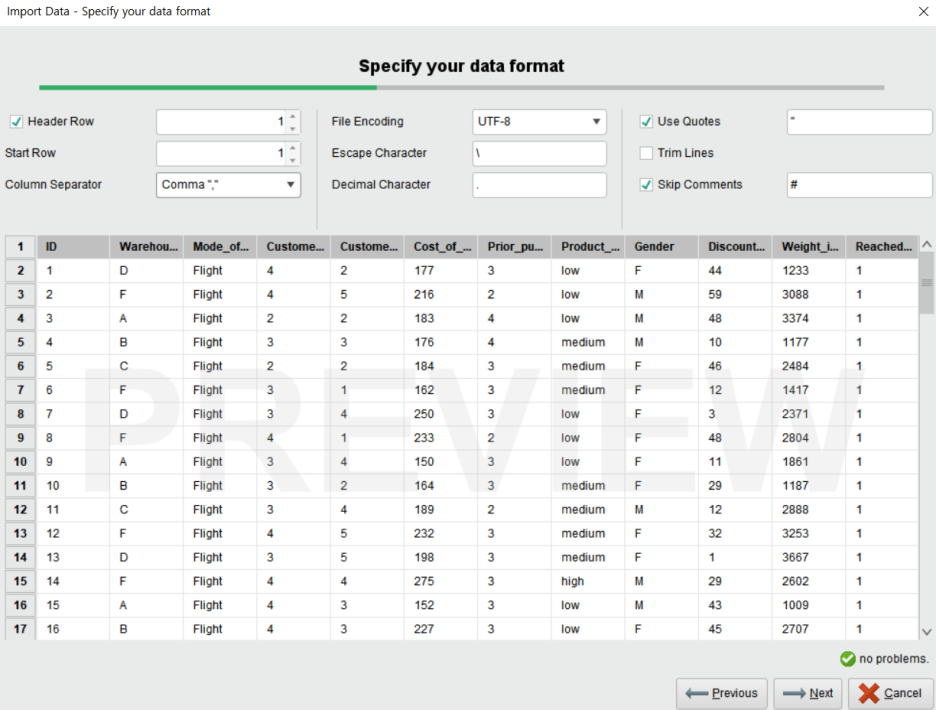
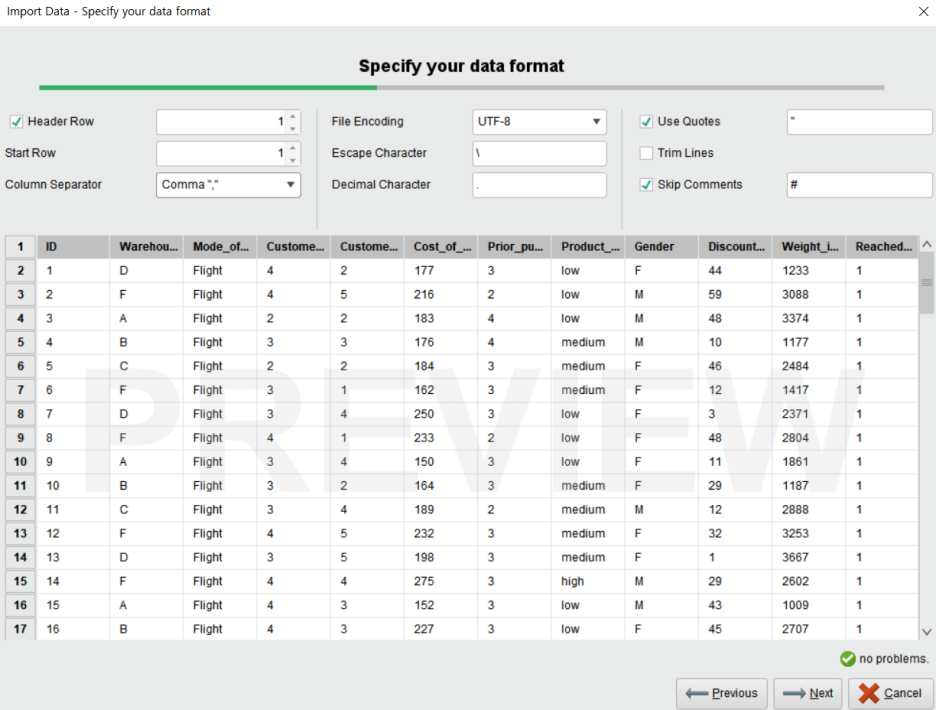
다음은 컬럼별로 포맷을 지정하는 단계입니다.
• Change Type : 데이터 유형 지정 (polynominal / binominal / real / integer / date_time / date / time)
• Change Role : 데이터 역할 지정 (label / id / weight)
• Rename Column: 컬럼명 변경
• Exclude Column : 해당 컬럼은 불러오지 않기
아래의 no problems의 체크가 뜨면 Finish를 클릭하여 데이터 지정을 마무리해줍니다.
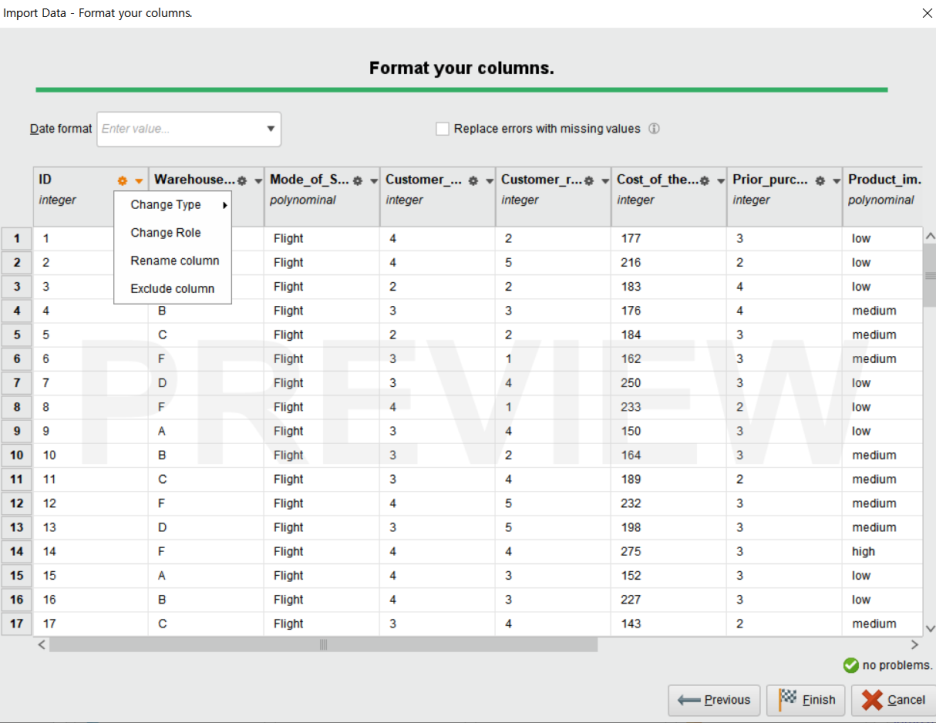
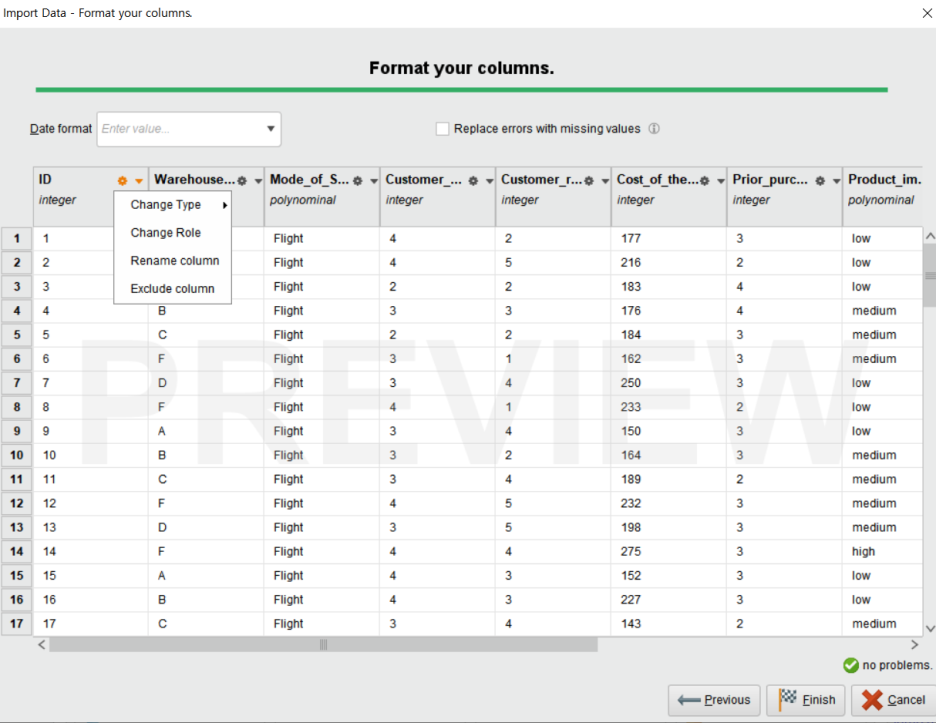
추후 데이터 포맷에 대한 수정이 필요할 경우,
Parameters 패널에서 변경이 가능하므로 위와 같은 과정을 반복하지 않아도 됩니다!!
Read CSV 오퍼레이터의out포트(=출력)를res포트(=결과)에 연결하고 F11 또는 ▶을 클릭하여 프로세스 실행합니다.
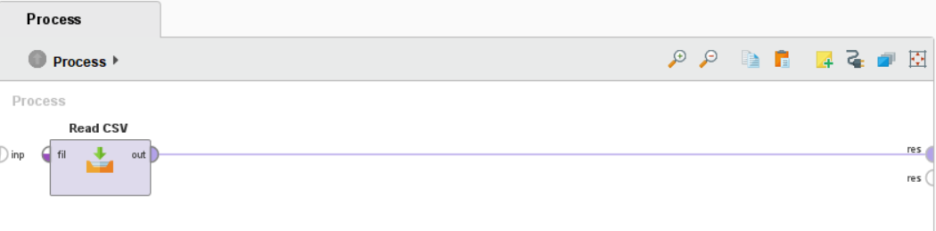
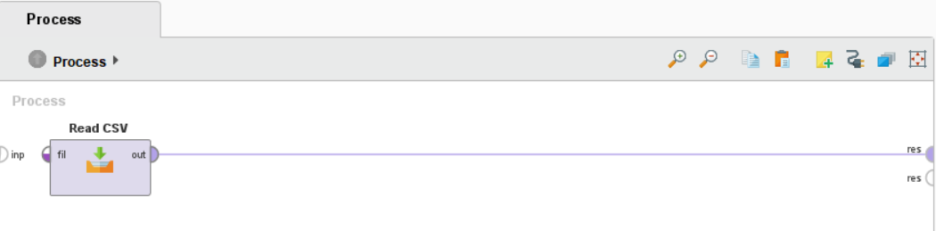
실행이 완료되면 Results에서 결과를 보여줍니다.
컬럼명을 클릭하면 값의 오름차순 / 내림차순이 가능합니다.
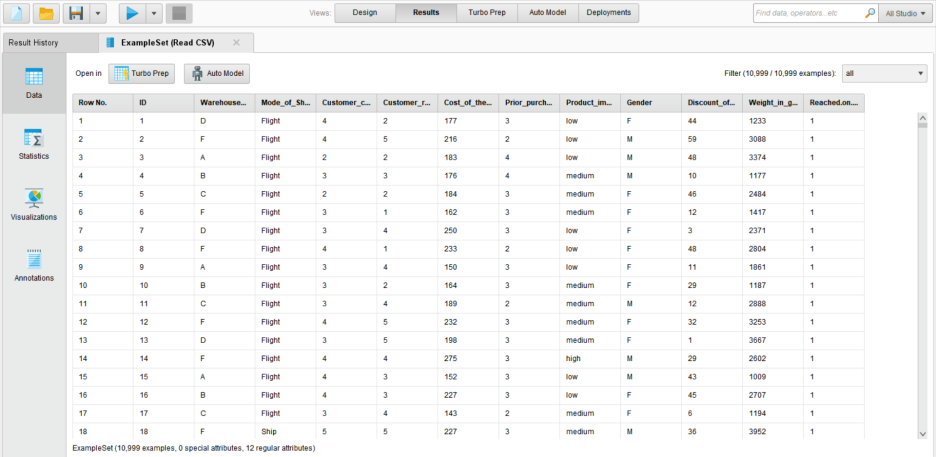
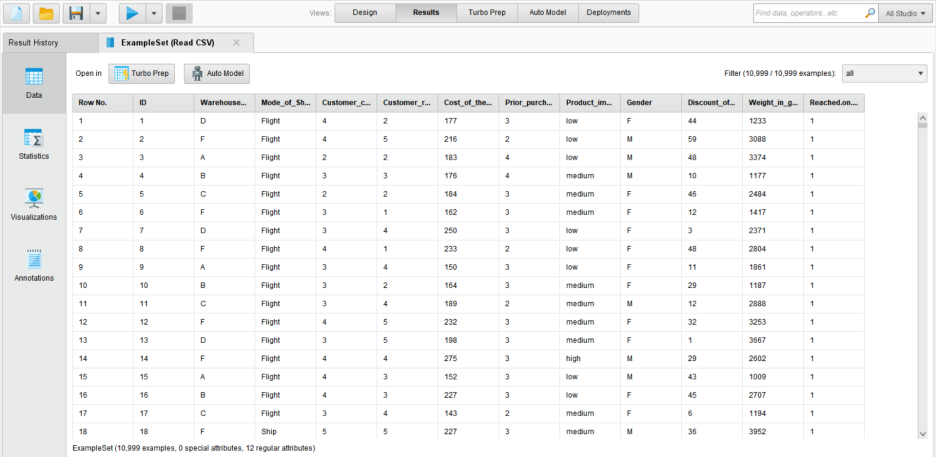
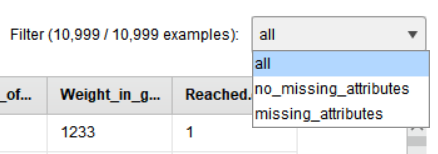
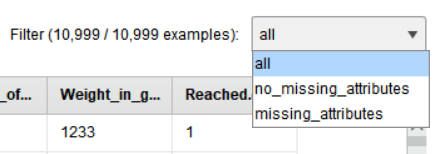
우측 상단에 Filter 기능을 통해 데이터를 확인할 수 있습니다.
• all : 모든 데이터 확인
• no_missing_attributes : 결측치가 없는 데이터만 확인
• missing_attributes : 결측치가 존재하는 데이터만 확인
래피드마이너 셀프스터디 2편의 시각화와 그룹핑으로 데이터 탐색하기로 이어집니다~
*해당 글은 래피드마이너 서포터즈 1기 조유진학생의 포스팅을 바탕을 작성되었습니다. (https://blog.naver.com/wiss_00/223025996132)
![[RapidMiner 래피드마이너 셀프 스터디] 4편 : 전처리 (2) – 데이터 스케일링(Scaling)](https://blog.altair.co.kr/wp-content/uploads/사진자료-알테어-래피드마이너-2023-500x383.jpg)
![[RapidMiner 래피드마이너 셀프 스터디] #2-1 시각화와 그룹핑으로 데이터 탐색하기](https://blog.altair.co.kr/wp-content/uploads/Rapidminer-로고-1-500x383.png)