
래피드마이너 셀프스터디 3편 : 데이터 병합 & 행열 전환
데이터의 용량이 커서 분할 저장된 경우,데이터가 각각 수집된 경우 등등여러 개로 분할된 데이터를 합치는 방법과 데이터의 행과 열을 바꾸는 방법을 래피드마이너로 실습해 보겠습니다!
저번 포스팅 바로가기 : https://blog.altair.co.kr/rapidminer-self-study-visualization-grouping/
데이터 붙이기
– Append
(실습을 위해 마케팅 캠페인 데이터(출처: Kaggle)에서 임의로 일부만 추출하여 구성함)
위의 실습 데이터를 다운로드한 후, 래피드마이너에서 데이터를 로딩하겠습니다.
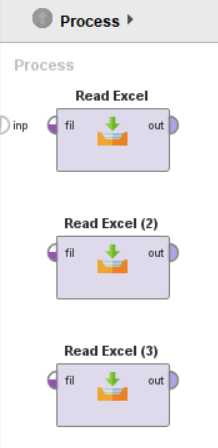
Read Excel 오퍼레이터를 복사하여 시트 개수만큼 준비하고, 각각의 오퍼레이터별로 시트를 지정해 줍니다.
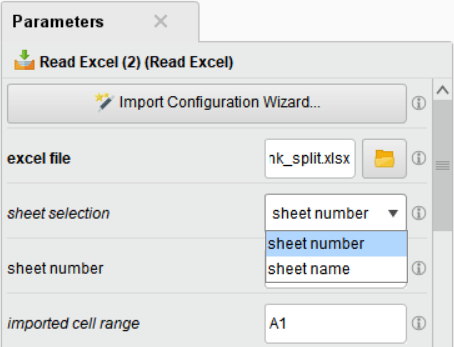
(Parameters 패널의 sheet selection – sheet number/sheet name 으로 엑셀 시트를 지정)
– Read Excel = sheet number : 1
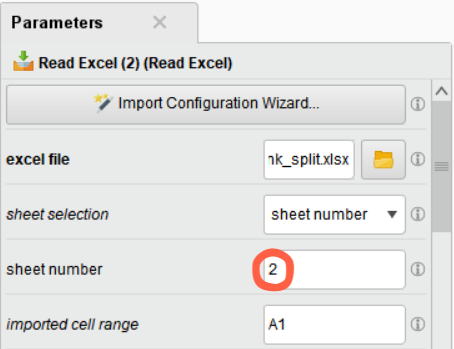
– Read Excel (2) = sheet number : 2
– Read Excel (3) = sheet number : 3



● Append
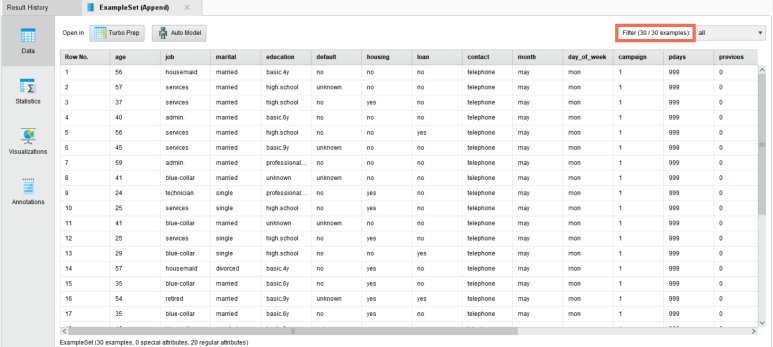
현재 실습 데이터처럼 sheet 1, 2, 3의 데이터 구조가 동일할 때 수직 통합(행 + 행)하여 하나의 데이터로 병합할 수 있는 오퍼레이터입니다.
※ 데이터 타입 확인
– 컬럼명 & 컬럼 개수 & 데이터 타입이 일치해야 합니다. (컬럼 순서는 상관 없음)
세 개의 데이터를 각각 지정한 Read Excel 오퍼레이터의 out 포트(=출력)를 Append 오퍼레이터의 exa 포트(=예제)에 연결하고 mer 포트(=병합)와 res 포트(=결과)를 연결하여 실행합니다.

※ 포트 연결 순서 확인 (하나씩 추가하기)
– Append의 1번 exa 포트로 연결된 데이터 → 위에 위치
– Append의 2번 exa 포트로 연결된 데이터 → 중간에 위치
– Append의 3번 exa 포트로 연결된 데이터 → 아래에 위치

↓ 3개의 데이터가 아래(행 단위)로 합쳐진 것을 확인할 수 있습니다. ↓
데이터 조인 & 집합
– 조인 기능 : Join
– 집합 기능 : Union / Set Minus / Intersect / Cartesioan Product
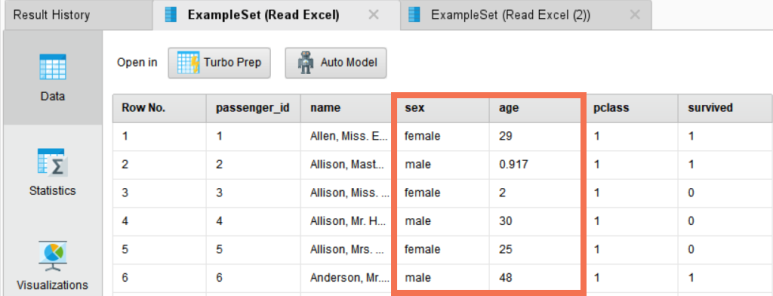
데이터 조인과 집합은 타이타닉 데이터셋의 일부로 실습해 보겠습니다.
Personal info 시트에는 타이타닉호 탑승자의 개인정보가 있고, Ticket info 시트에는 티켓정보가 있습니다.
이 두 데이터는 다른 시트에 저장되어 있지만 고유번호인 passenger_id를 통해 같은 탑승자임을 확인할 수 있습니다!

● Join
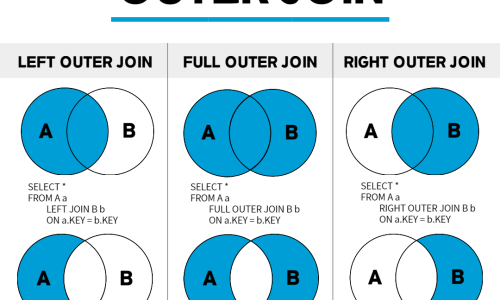
데이터베이스에서 사용되는 개념인 Join을 래피드마이너에서도 구현할 수 있습니다.
Join은 관계형 데이터베이스에서 두 개 이상의 테이블들을 연결 또는 결합하여 데이터를 출력하는 작업입니다.
* 조인 관련 개념 익히기 : https://hongong.hanbit.co.kr/sql-%EA%B8%B0%EB%B3%B8-%EB%AC%B8%EB%B2%95-joininner-outer-cross-self-join/
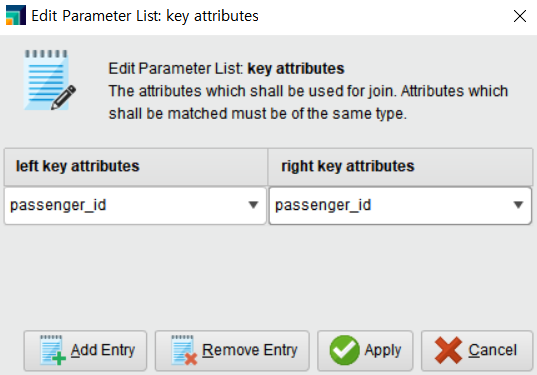
그럼 Passenger_id를 기준으로 두 개의 데이터(시트)를 하나의 데이터로 조인해 보겠습니다.
Join 오퍼레이터의 lef 포트에는 왼쪽에 올 데이터를 연결하고 rig 포트에는 오른쪽에 올 데이터를 연결합니다.
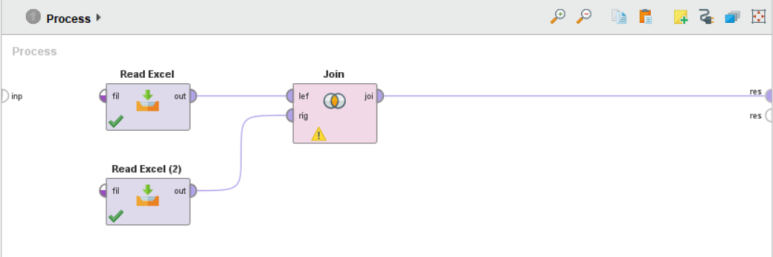
※ 왼쪽 데이터와 오른쪽 데이터 연결 주의!
※ 조인 유형과 key 지정
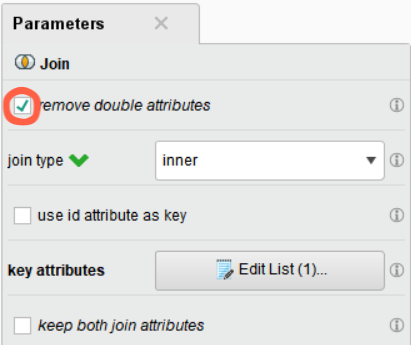
• remove double attributes : 중복된 컬럼 제외
• join type : 조인 유형 지정 (inner / left / right / outer)
• use id attribute as key : 컬럼의 역할(role)이 id로 지정된 컬럼을 key로 사용
• key attributes : key로 사용할 컬럼을 지정 (여러 개 가능)
조인 유형 | 조인 결과 |
inner join | 두 데이터의 공통된 정보 |
left join | 왼쪽 데이터의 모든 정보 + 왼쪽과 오른쪽의 공통된 정보 |
right join | 오른쪽 데이터의 모든 정보 + 오른쪽과 왼쪽의 공통된 정보 |
outer join | 모든 데이터를 조인 |
* inner join은 공통된 값만 반환하므로 결측값이 발생하지 않음.
* left join / right join / outer join은 결측값 발생 가능성이 높음.
remove double attributes 체크하여 중복되는 컬럼(name, pclass, survived)을 제거,
두 데이터에 공통으로 존재하는 값으로만 조인하기 위해서 join type을 inner(내부 조인)로 지정,
key attributes를 passenger_id로 설정합니다.


inner(내부조인)으로 설정했기 때문에 Passenger_id를 기준으로 공통된 데이터만 병합되었습니다.


INNER JOIN 결과
● Union
Union 은 데이터를 단순히 합쳐놓는 합집합의 기능을 수행하는 오퍼레이터입니다.
SQL의 집합 연산자인 UNION ALL(중복된 행을 포함하는 합집합)과 같은 작업을 수행합니다.
Read Excel 오퍼레이터 2개의 out 포트(=출력)를 Union 오퍼레이터의 exa 포트(=예제)에 연결하고 uni 포트(=합집합)와 res 포트(=결과)를 연결하여 실행합니다.

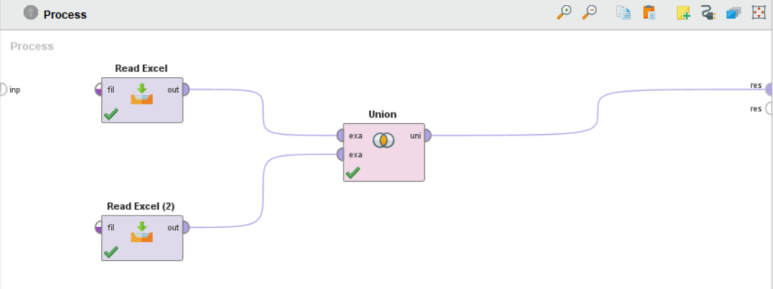
Union은 단순히 행을 합치기 때문에 존재하지 않는 값은 ?로 비워져서 나타나고,
100개의 예제가 있는 데이터 두 개를 합쳤기 때문에 최종 결과는 200개로 나타납니다.
(일반적으로, UNION ALL 집합 연산자는 데이터가 상호 배타적인 경우에 주로 사용함)


UNION 결과
< 데이터 병합 관련 오퍼레이터 차이점 정리>
※ 헷갈릴만한 개념?
① 조인과 집합의 차이점?
= 조인은 key 속성을 필요로 하고 두 개의 데이터를 컬럼 단위로 결합한다.
= 집합은 key 속성이 필요 없으며 두 개의 데이터를 행 단위로 결합한다.
② Union ALL과 FULL OUTER JOIN의 차이점?
= Union ALL은 행의 합집합으로 위아래로 결합된다.
= FULL OUTER JOIN은 열의 합집합으로 옆으로 결합된다.
③ Append와 Union의 차이점?
= Append는 데이터 구조(컬럼)가 같아야 한다.
= Union은 컬럼과 데이터 값이 달라도 합치는 것이 가능하다.


데이터 행열 전환
– Transpose
● Transpose
우리가 사용하는 데이터는 보통 열(컬럼)과 행(데이터)로 이루어져 있습니다.
데이터를 수집해서 사용하다 보면 일부 공공데이터 및 통계표들이 사용 형식에 맞지 않게 기록되어 있는 경우가 종종 있습니다.
※ 관계형 데이터베이스에 저장되는 일반적인 데이터 형식
· 열(column, 속성) : 동일한 의미 & 도메인(속성이 가질 수 있는 값의 범위)을 가지는 값들로 구성됨
· 행(row, 튜플) : 하나의 사례(데이터)를 의미함 (행 하나가 한 사람의 정보를 나타냄)

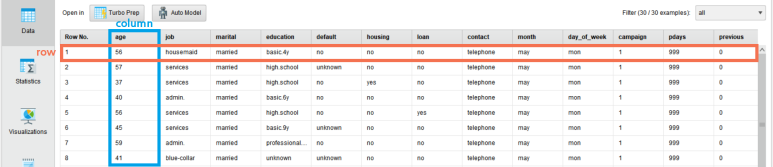
다음과 같이 데이터가 누워있는 경우를 예로 들어 보겠습니다.
이런 경우에는 일반적인 데이터 형식에 맞게끔 누워있는 데이터를 세우는 작업을 수행해야 합니다.


Transpose 오퍼레이터를 사용하여 현재의 행 → 컬럼 & 현재의 컬럼 → 행으로 전환해 보겠습니다.
Read Excel 오퍼레이터의 out 포트(=출력)를 Transpose 오퍼레이터의 exa 포트(=예제)로 연결한 후 res 포트(=결과)를 연결합니다.


실행 결과, 우리가 흔히 아는 데이터의 형태로 행과 열이 전환되었습니다.

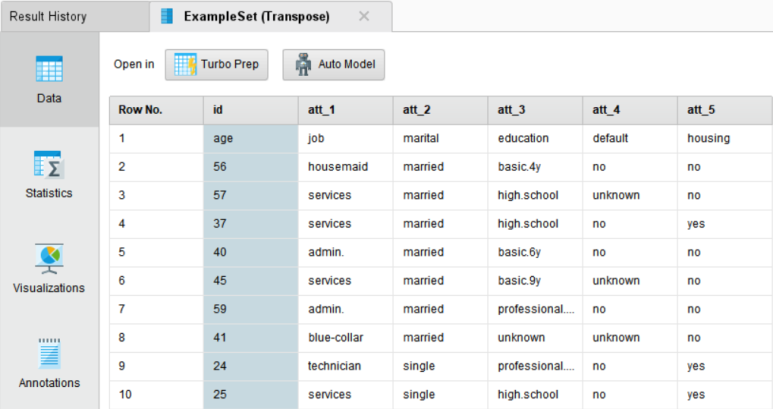
Transpose 오퍼레이터는 단순히 행열 전환만 수행하기 때문에 사진과 같이 컬럼명이 지정되지 않은 형태로 출력됩니다.
첫 번째 행을 컬럼명으로 사용하기 위해 다음과 같은 작업을 추가로 수행해 주었습니다.
Transpose 사이에 Write Excel 를 추가하여 Read Excel 오퍼레이터와 연결합니다.
⇒ Transpose 오퍼레이터의 출력인 exa 포트와 Read Excel 오퍼레이터를 입력인 fil 포트가 일치하지 않아 에러가 발생하기 때문에 Write Excel 오퍼레이터를 추가로 배치하였습니다.

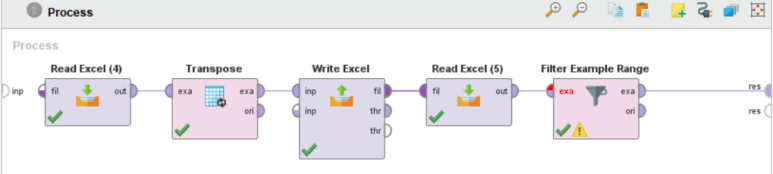
Read Excel 오퍼레이터의 파라미터를 다음과 같이 조정합니다.
– first row as names (첫 행을 컬럼명으로 사용) 체크 해제
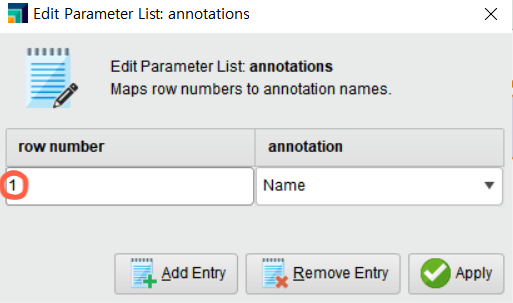
– annotations 을 클릭하여 첫 행(1)을 Name으로 지정



실행 결과, 첫 번째 행이 컬럼명으로 변경되었지만 기존의 컬럼(att_1 ~ id)이 첫 번째 행으로 인식되고 있습니다.

Filter Examples Range 오퍼레이터를 사용하여 인덱스 범위 지정을 통해 첫 번째 행을 제외시킵니다.
– first example을 2번째 행으로 지정
– lastt example을 10번째 행으로 지정
이렇게 지정하면 1번 행이 제외되고, 2번 행부터 10번 행까지를 데이터로 반환하게 됩니다.


위의 과정을 모두 연결하여 실행하면 컬럼명이 제대로 지정된 데이터를 확인할 수 있습니다!
다음 포스팅을 기대해주세요!

![[RapidMiner 래피드마이너 셀프 스터디] 4편 : 전처리 (2) – 데이터 스케일링(Scaling)](https://blog.altair.co.kr/wp-content/uploads/사진자료-알테어-래피드마이너-2023-500x383.jpg)
![[RapidMiner 래피드마이너 셀프 스터디] #2-1 시각화와 그룹핑으로 데이터 탐색하기](https://blog.altair.co.kr/wp-content/uploads/Rapidminer-로고-1-500x383.png)