
래피드마이너 셀프스터디 2편 : 시각화와 그룹핑으로 데이터 탐색하기
– 한국알테어 데이터분석 인턴 조유진 –
저번 포스팅에 이어서 바로 시작합니다!
저번 포스팅 바로가기 : https://blog.altair.co.kr/rapidminer-self-study-visualization-grouping/
래피드마이너로 데이터의 기본적인 통계값을 탐색해보는 과정을 실습해보겠습니다.
데이터 탐색하기 (2)
– 상관 분석
– 집계표 / 빈도표
– 피벗 테이블
위 과정에서 기초 통계량과 그래프로 각각 데이터의 분포를 확인하였다면,
지금부터는 두 개 이상의 변수를 조합하여 데이터를 탐색해보겠습니다.
● Correlation Matrix
두 변수 간의 선형적 상관 관계를 계산하는 상관 분석(Correlation Analysis)은 Correlation Matrix 오퍼레이터로 확인할 수 있습니다.
상관 분석은 주로 회귀분석 전, 종속변수와 독립변수 간의 상관성 또는 독립변수 간의 상관성을 확인하기 위해 진행합니다.
지금은 수치형 변수 간의 상관 계수만을 간단히 확인해보겠습니다.
※ 범주형 및 문자형 변수는 수치 계산이 불가능합니다.
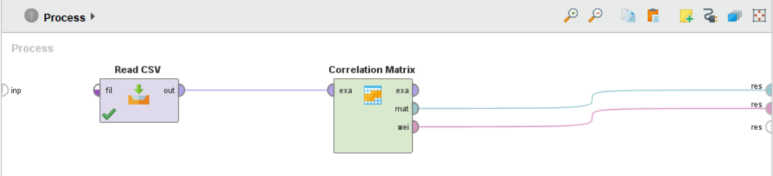

Read CSV 오퍼레이터의 out 포트(=출력)를 Correlation Matrix 오퍼레이터의 exa 포트(=예제)에 연결하고 mat 포트(=행렬)와 wei 포트(=가중치)를 res 포트(=결과)에 연결해줍니다.
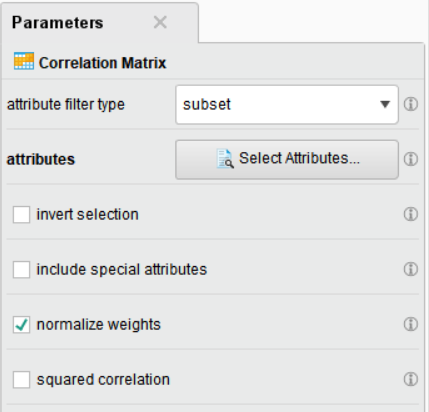
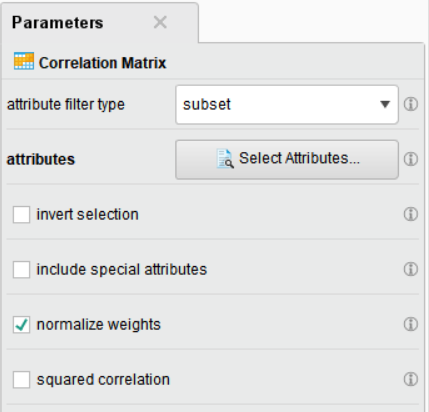
• attribute filter type : 변수 선택 방법 지정
• attributes : 특정 변수 지정
• invert selection : 선택한 변수의 반대로 지정
• include special attributes : id, weight, label 등과 같이 특정 역할로 지정된 변수를 포함
• normalize weights : 가중치 정규화 여부
• squared correlation : 상관관계 제곱 여부
수치형 변수만을 확인하기 위해 파라미터를 설정해줍니다.
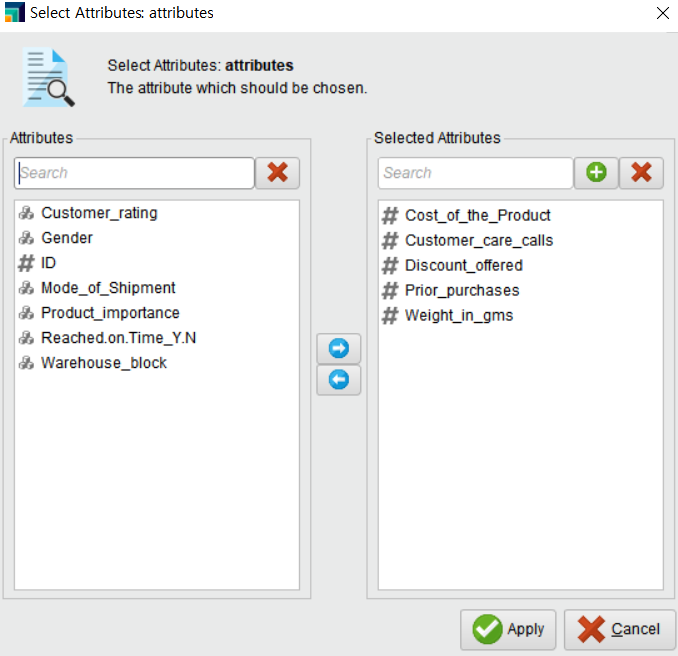
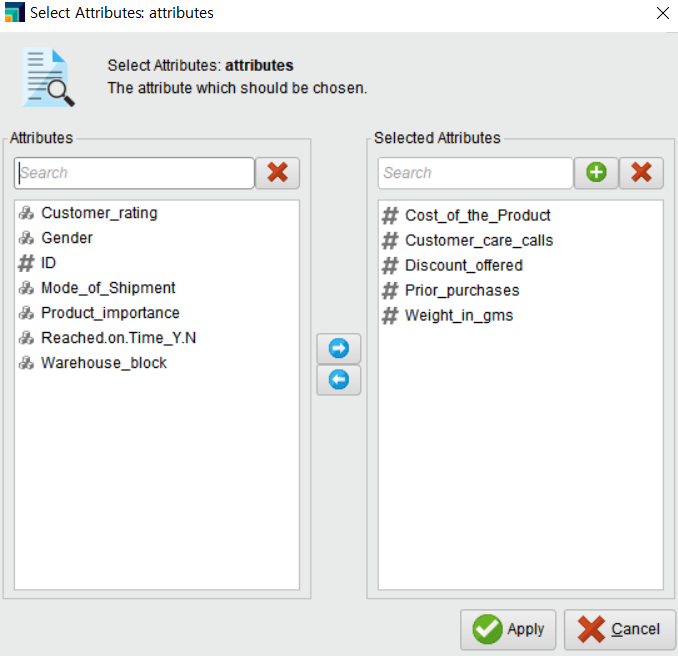
저는 여러 개의 변수를 직접 선택하기 위해 subset으로 변수를 각각 선택해 주었습니다.


※ Correlation Matrix 오퍼레이터는 피어슨 상관계수로 계산합니다.
Data / Pairwise Table / Matrix Visualization / Annotation을 지원하고 있으므로 본인이 보기 편리한 걸로 확인하시면 됩니다.
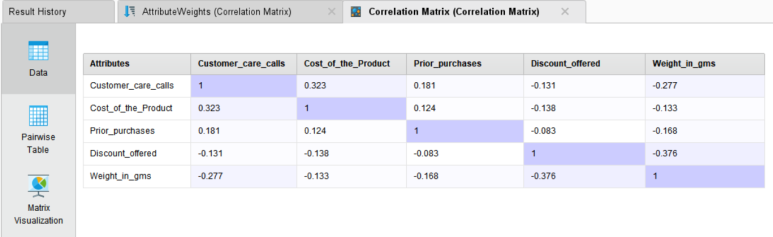
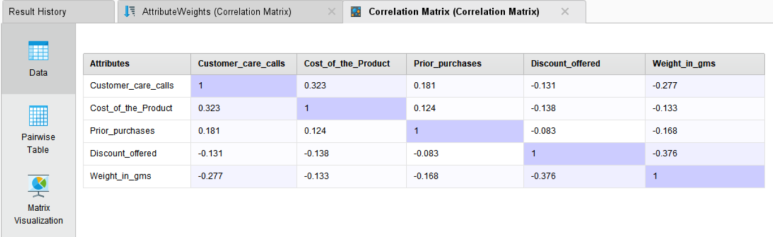





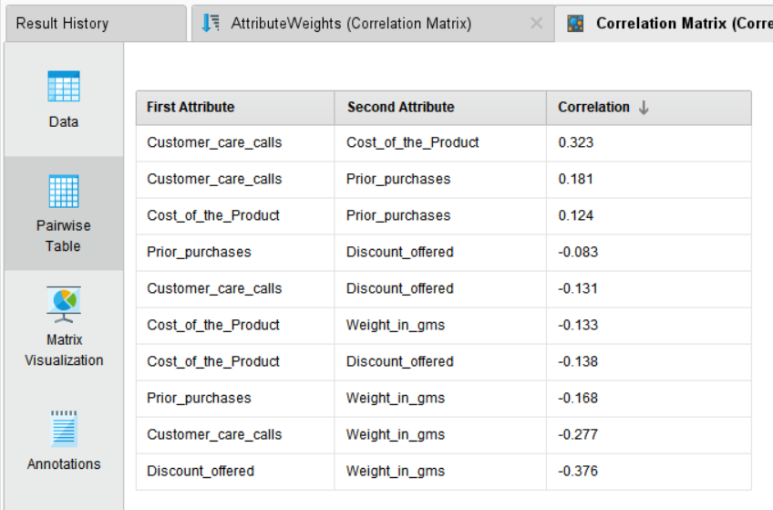
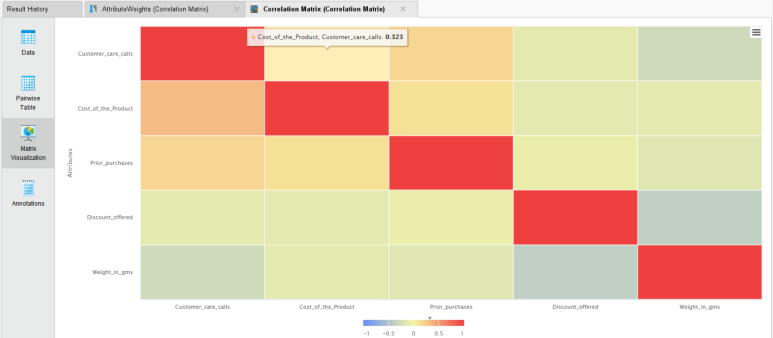
▶▶ 배송 문의 전화 횟수와 상품 가격 간의 약한 양의 상관관계를 보이고 있으며, 반대로 할인과 상품 무게 간에는 약한 음의 상관관계를 보이는 것을 확인할 수 있습니다. 상품 가격이 조금 비싸지면 상대적으로 배송 전화 문의도 다소 증가하는 것으로 보입니다.
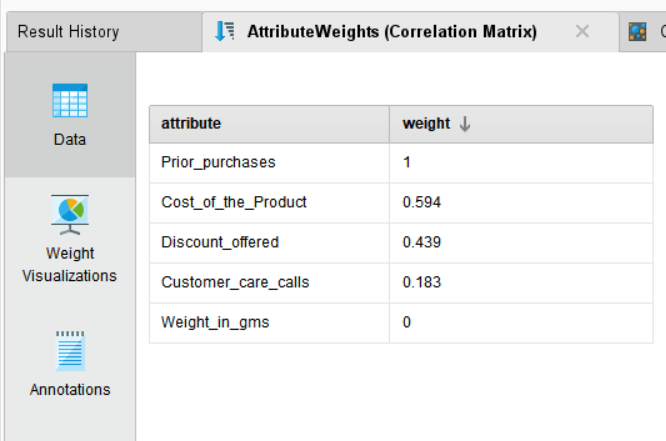
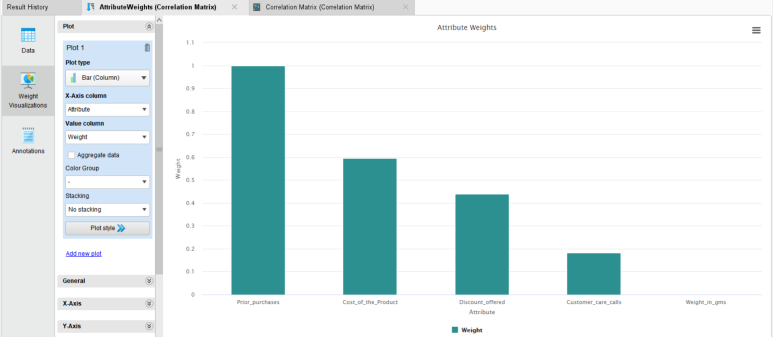
래피드마이너는 상관관계를 기반으로 변수의 가중치를 출력해줍니다. (wei 포트 결과값)


● Aggregate
SQL의 집계 함수와 유사한 기능을 구현하는 Aggregate 오퍼레이터는 변수들의 조합으로 그룹을 만들어 계산을 수행합니다.
그룹별로 다양한 집계 결과를 확인할 때 사용합니다.

Read CSV 오퍼레이터의 out 포트(=출력)를 Aggregate 오퍼레이터의 exa 포트(=예제)에 연결하고 exa 포트(=집계)를 res 포트(=결과)에 연결해줍니다.


집계 기준(변수)과 집계 함수(계산)는 파라미터를 통해서 설정해줍니다.
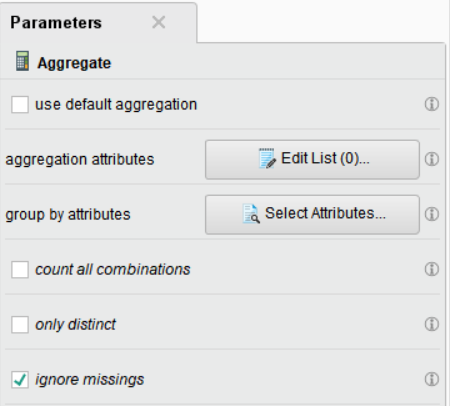
• use default aggregation : 체크시 변수 선택 방법 지정 등 추가 파라미터 설정 가능
• aggregation attributes : 변수별로 확인하고자 하는 통계값을 지정
• group by attributes : 집계 기준(그룹)으로 사용할 변수를 지정
• count all combinations : 가능한 모든 조합 생성 여부 (많은 조합은 계산량 및 시간이 늘어날 수 있음을 주의)
• only distinct : 고유값만 사용하여 계산
• ignore missings : 결측값을 제외하고 계산

※ 알아보고자 하는 주제에 따라 변수와 집계 함수를 적절히 조합해야 합니다!
※ 범주형 변수 + 수치형 변수 = 그룹별 집계표
※ 범주형 변수 + 범주형 변수 = 빈도표 또는 교차표(cross-table)
Aggregate 오퍼레이터로 해당 데이터에서 궁금한 점 2가지를 간단히 확인해보겠습니다.
Q1. 고객 등급별로 구매한 상품 가격이 다를까?
※ 고객 등급별로? → groub by attributes : Customer_rating 선택
※ 상품 가격에 대해서? → aggregation attribute : Cost_of_the_Product 선택
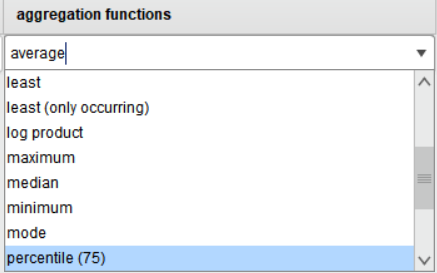
※ 어떤 계산을? → aggregation functions : sum(합계) / average(평균) / minimum(최소) / maximum(최대) 선택

.png?type=w773)
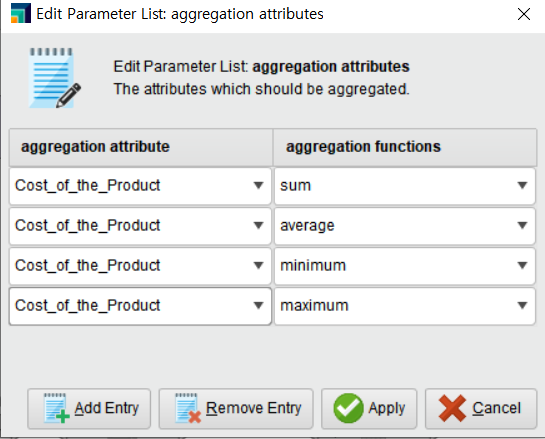
▶▶ 구매된 상품의 최소 가격과 최대 가격은 고객 등급별로 거의 차이가 없습니다. 가장 높은 등급을 의미하는 5등급 고객들의 금액 합계가 458,439$로 다른 (낮은) 등급의 고객들에 비해 다소 낮은 것을 확인할 수 있습니다.
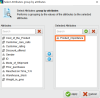
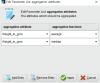
Q2. 상품 중요도별로 무게가 다를까?
※ 상품 중요도별로? → groub by attributes : Product_importance 선택
※ 무게에 대해서? → aggregation attribute : Weight_in_gms 선택
※ 어떤 계산을? → aggregation functions : average(평균) / median(중앙값) 선택

.png?type=w773)
.png?type=w773)
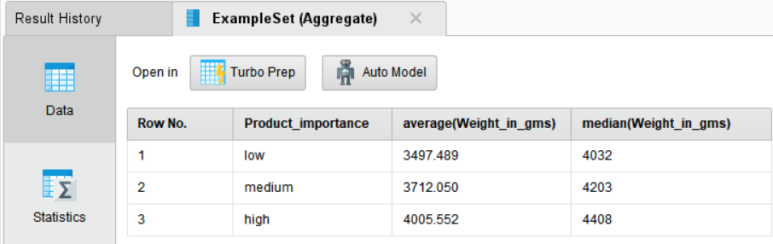
▶▶ 중요도가 낮은(low) 상품은 무게의 평균값과 중앙값 모두 낮게 나타났습니다. 중요한 상품일수록 무게가 비교적 무거운 것을 알 수 있습니다.
● Pivot
Pivot 은 기존 자료를 활용하여 행과 열을 재배치하고 합계, 평균 등으로 요약한 새로운 테이블을 만들어 주는 오퍼레이터입니다.
주로 엑셀에서 통계표 및 보고서를 작성할 때 많이 사용되는 기능입니다.
Read CSV 오퍼레이터의 out 포트(=출력)를 Pivot 오퍼레이터의 inp 포트(=입력)에 연결하고 out 포트(=출력)를 res 포트(=결과)에 연결합니다.
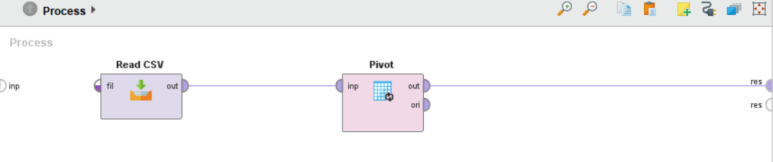

• group by attributes : 피벗 테이블의 행 지정 (2개 이상의 변수 선택시 조합 생성)
• column grouping attribute : 피벗 테이블의 컬럼 지정
• aggregation attributes : 피벗 테이블의 각 셀을 계산할 변수와 집계 함수 지정
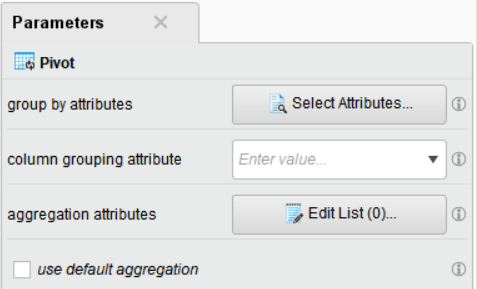

Pivot 오퍼레이터와 Aggregate 오퍼레이터는 같은 정보를 제공하지만 다른 형태로 표현됩니다.

Aggregate 결과

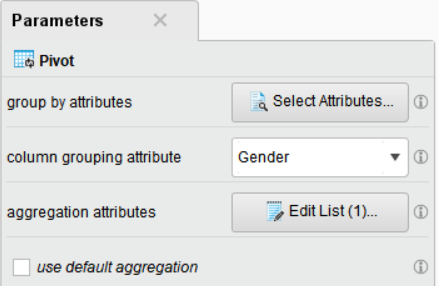

Pivot 결과 (1)

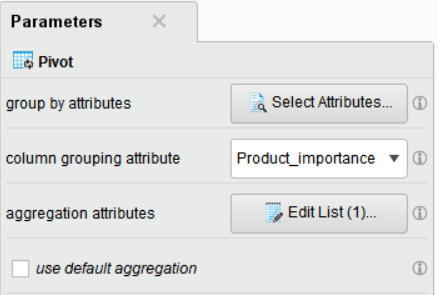

Pivot 결과 (2)

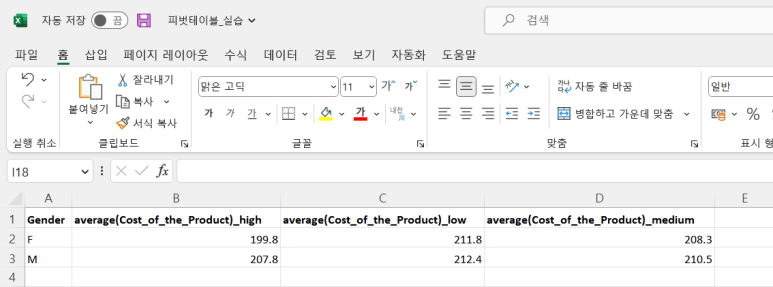
▶▶ 남성(M) 고객의 평균 구매 가격을 상품 중요도 별로 살펴보았을 때, 상품 중요도가 낮은(low) 제품의 구매 가격이 약 211$로 가장 높게 나타났습니다. 여성(M) 고객 역시 상품 중요도가 낮은(low) 제품의 구매 가격이 약 212$로 가장 높게 나타난 것을 알 수 있습니다. 남성과 여성 모두 상품 중요도가 높은(high) 상품의 매출이 비교적 적은 것을 확인하였습니다.
Aggregate 오퍼레이터와 Pivot 오퍼레이터의 차이점을 설명한 영상입니다!!
데이터 생성하기
– 엑셀 파일 생성
위에서 만든 피벗 테이블을 엑셀 파일로 저장해보겠습니다.
Write CSV 또는 Write Excel 오퍼레이터를 사용하여 엑셀 파일을 작성할 수 있습니다.
Pivot 오퍼레이터의 out 포트(=출력)를 Write Excel 오퍼레이터의 inp 포트(=입력)에 연결하고 thr 포트(=전달)를 res 포트(=결과)에 연결해줍니다.
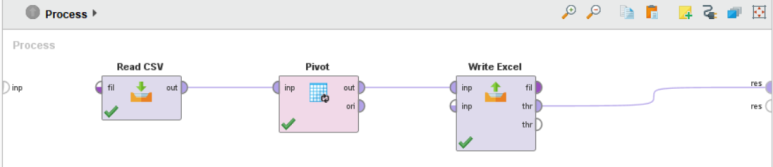

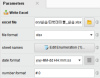
• excel file : 저장 경로(폴더) 선택
• file format : 파일 확장자 지정 (xls / xlsx)
• sheet names : 시트 이름 지정
.png?type=w773)

지정한 폴더에 가서 생성된 엑셀 파일을 확인하면 끝입니다!!

다음 편을 기대해주세요~
![[RapidMiner 래피드마이너 셀프 스터디] 4편 : 전처리 (2) – 데이터 스케일링(Scaling)](https://blog.altair.co.kr/wp-content/uploads/사진자료-알테어-래피드마이너-2023-500x383.jpg)
![[RapidMiner 래피드마이너 셀프 스터디] #2-1 시각화와 그룹핑으로 데이터 탐색하기](https://blog.altair.co.kr/wp-content/uploads/Rapidminer-로고-1-500x383.png)